 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Transfer Learning for Remote Sensing Image-Text Retrieval
Paper and Code


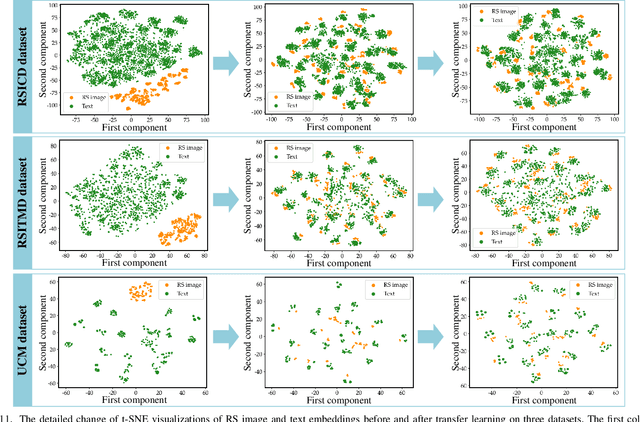

Vision-and-language pre-training (VLP) models have experienced a surge in popularity recently. By fine-tuning them on specific datasets, significant performance improvements have been observed in various tasks. However, full fine-tuning of VLP models not only consumes a significant amount of computational resources but also has a significant environmental impact. Moreover, as remote sensing (RS) data is constantly being updated, full fine-tuning may not be practical for real-world applications. To address this issue, in this work, we investigate the parameter-efficient transfer learning (PETL) method to effectively and efficiently transfer visual-language knowledge from the natural domain to the RS domain on the image-text retrieval task. To this end, we make the following contributions. 1) We construct a novel and sophisticated PETL framework for the RS image-text retrieval (RSITR) task, which includes the pretrained CLIP model, a multimodal remote sensing adapter, and a hybrid multi-modal contrastive (HMMC) learning objective; 2) To deal with the problem of high intra-modal similarity in RS data, we design a simple yet effective HMMC loss; 3) We provide comprehensive empirical studies for PETL-based RS image-text retrieval. Our results demonstrate that the proposed method is promising and of great potential for practical applications. 4) We benchmark extensive state-of-the-art PETL methods on the RSITR task. Our proposed model only contains 0.16M training parameters, which can achieve a parameter reduction of 98.9% compared to full fine-tuning, resulting in substantial savings in training costs. Our retrieval performance exceeds traditional methods by 7-13% and achieves comparable or better performance than full fine-tuning. This work can provide new ideas and useful insights for RS vision-language tasks.