 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSide Auth: Synthesizing Virtual Sensors for Authentication
Jan 27, 2023While the embedded security research community aims to protect systems by reducing analog sensor side channels, our work argues that sensor side channels can be beneficial to defenders. This work introduces the general problem of synthesizing virtual sensors from existing circuits to authenticate physical sensors' measurands. We investigate how to apply this approach and present a preliminary analytical framework and definitions for sensor side channels. To illustrate the general concept, we provide a proof-of-concept case study to synthesize a virtual inertial measurement unit from a camera motion side channel. Our work also provides an example of applying this technique to protect facial recognition against silicon mask spoofing attacks. Finally, we discuss downstream problems of how to ensure that side channels benefit the defender, but not the adversary, during authentication.
Side Eye: Characterizing the Limits of POV Acoustic Eavesdropping from Smartphone Cameras with Rolling Shutters and Movable Lenses
Jan 26, 2023



Our research discovers how the rolling shutter and movable lens structures widely found in smartphone cameras modulate structure-borne sounds onto camera images, creating a point-of-view (POV) optical-acoustic side channel for acoustic eavesdropping. The movement of smartphone camera hardware leaks acoustic information because images unwittingly modulate ambient sound as imperceptible distortions. Our experiments find that the side channel is further amplified by intrinsic behaviors of Complementary metal-oxide-semiconductor (CMOS) rolling shutters and movable lenses such as in Optical Image Stabilization (OIS) and Auto Focus (AF). Our paper characterizes the limits of acoustic information leakage caused by structure-borne sound that perturbs the POV of smartphone cameras. In contrast with traditional optical-acoustic eavesdropping on vibrating objects, this side channel requires no line of sight and no object within the camera's field of view (images of a ceiling suffice). Our experiments test the limits of this side channel with a novel signal processing pipeline that extracts and recognizes the leaked acoustic information. Our evaluation with 10 smartphones on a spoken digit dataset reports 80.66%, 91.28%, and 99.67% accuracies on recognizing 10 spoken digits, 20 speakers, and 2 genders respectively. We further systematically discuss the possible defense strategies and implementations. By modeling, measuring, and demonstrating the limits of acoustic eavesdropping from smartphone camera image streams, our contributions explain the physics-based causality and possible ways to reduce the threat on current and future devices.
Private Eye: On the Limits of Textual Screen Peeking via Eyeglass Reflections in Video Conferencing
May 08, 2022

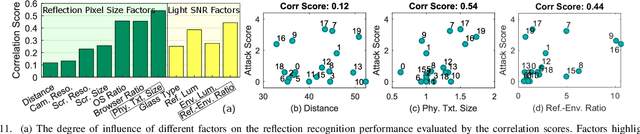

Personal video conferencing has become the new norm after COVID-19 caused a seismic shift from in-person meetings and phone calls to video conferencing for daily communications and sensitive business. Video leaks participants' on-screen information because eyeglasses and other reflective objects unwittingly expose partial screen contents. Using mathematical modeling and human subjects experiments, this research explores the extent to which emerging webcams might leak recognizable textual information gleamed from eyeglass reflections captured by webcams. The primary goal of our work is to measure, compute, and predict the factors, limits, and thresholds of recognizability as webcam technology evolves in the future. Our work explores and characterizes the viable threat models based on optical attacks using multi-frame super resolution techniques on sequences of video frames. Our experimental results and models show it is possible to reconstruct and recognize on-screen text with a height as small as 10 mm with a 720p webcam. We further apply this threat model to web textual content with varying attacker capabilities to find thresholds at which text becomes recognizable. Our user study with 20 participants suggests present-day 720p webcams are sufficient for adversaries to reconstruct textual content on big-font websites. Our models further show that the evolution toward 4K cameras will tip the threshold of text leakage to reconstruction of most header texts on popular websites. Our research proposes near-term mitigations, and justifies the importance of following the principle of least privilege for long-term defense against this attack. For privacy-sensitive scenarios, it's further recommended to develop technologies that blur all objects by default, then only unblur what is absolutely necessary to facilitate natural-looking conversations.