 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible Triggering Kernels for Hawkes Process Modeling
Feb 03, 2022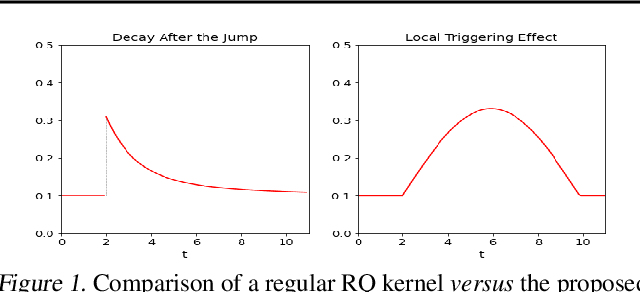

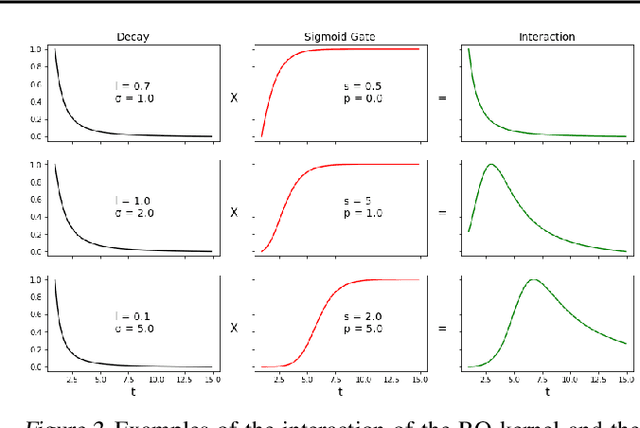
Recently proposed encoder-decoder structures for modeling Hawkes processes use transformer-inspired architectures, which encode the history of events via embeddings and self-attention mechanisms. These models deliver better prediction and goodness-of-fit than their RNN-based counterparts. However, they often require high computational and memory complexity requirements and sometimes fail to adequately capture the triggering function of the underlying process. So motivated, we introduce an efficient and general encoding of the historical event sequence by replacing the complex (multilayered) attention structures with triggering kernels of the observed data. Noting the similarity between the triggering kernels of a point process and the attention scores, we use a triggering kernel to replace the weights used to build history representations. Our estimate for the triggering function is equipped with a sigmoid gating mechanism that captures local-in-time triggering effects that are otherwise challenging with standard decaying-over-time kernels. Further, taking both event type representations and temporal embeddings as inputs, the model learns the underlying triggering type-time kernel parameters given pairs of event types. We present experiments on synthetic and real data sets widely used by competing models, while further including a COVID-19 dataset to illustrate a scenario where longitudinal covariates are available. Results show the proposed model outperforms existing approaches while being more efficient in terms of computational complexity and yielding interpretable results via direct application of the newly introduced kernel.