 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree-based RAG-Agent Recommendation System: A Case Study in Medical Test Data
Jan 06, 2025



We present HiRMed (Hierarchical RAG-enhanced Medical Test Recommendation), a novel tree-structured recommendation system that leverages Retrieval-Augmented Generation (RAG) for intelligent medical test recommendations. Unlike traditional vector similarity-based approaches, our system performs medical reasoning at each tree node through a specialized RAG process. Starting from the root node with initial symptoms, the system conducts step-wise medical analysis to identify potential underlying conditions and their corresponding diagnostic requirements. At each level, instead of simple matching, our RAG-enhanced nodes analyze retrieved medical knowledge to understand symptom-disease relationships and determine the most appropriate diagnostic path. The system dynamically adjusts its recommendation strategy based on medical reasoning results, considering factors such as urgency levels and diagnostic uncertainty. Experimental results demonstrate that our approach achieves superior performance in terms of coverage rate, accuracy, and miss rate compared to conventional retrieval-based methods. This work represents a significant advance in medical test recommendation by introducing medical reasoning capabilities into the traditional tree-based retrieval structure.
Adversarial Attack Against Images Classification based on Generative Adversarial Networks
Dec 24, 2024
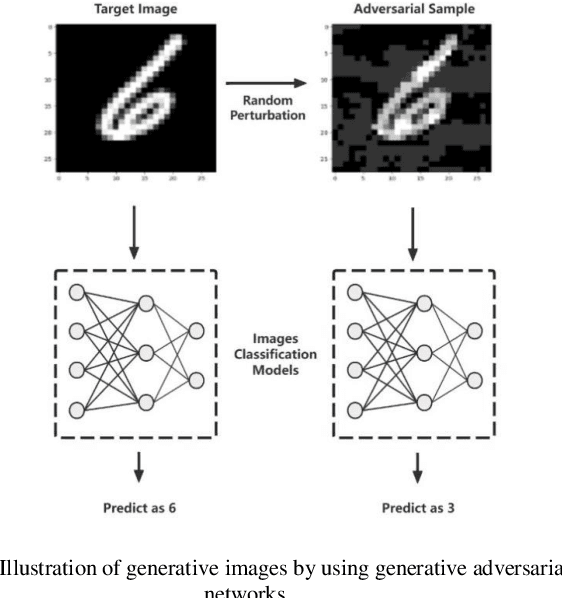
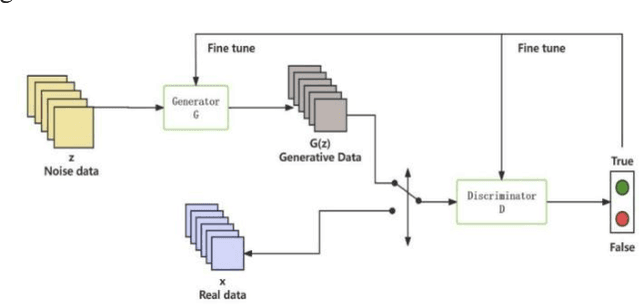

Adversarial attacks on image classification systems have always been an important problem in the field of machine learning, and generative adversarial networks (GANs), as popular models in the field of image generation, have been widely used in various novel scenarios due to their powerful generative capabilities. However, with the popularity of generative adversarial networks, the misuse of fake image technology has raised a series of security problems, such as malicious tampering with other people's photos and videos, and invasion of personal privacy. Inspired by the generative adversarial networks, this work proposes a novel adversarial attack method, aiming to gain insight into the weaknesses of the image classification system and improve its anti-attack ability. Specifically, the generative adversarial networks are used to generate adversarial samples with small perturbations but enough to affect the decision-making of the classifier, and the adversarial samples are generated through the adversarial learning of the training generator and the classifier. From extensive experiment analysis, we evaluate the effectiveness of the method on a classical image classification dataset, and the results show that our model successfully deceives a variety of advanced classifiers while maintaining the naturalness of adversarial samples.
Comprehensive Evaluation of Multimodal AI Models in Medical Imaging Diagnosis: From Data Augmentation to Preference-Based Comparison
Dec 07, 2024


This study introduces an evaluation framework for multimodal models in medical imaging diagnostics. We developed a pipeline incorporating data preprocessing, model inference, and preference-based evaluation, expanding an initial set of 500 clinical cases to 3,000 through controlled augmentation. Our method combined medical images with clinical observations to generate assessments, using Claude 3.5 Sonnet for independent evaluation against physician-authored diagnoses. The results indicated varying performance across models, with Llama 3.2-90B outperforming human diagnoses in 85.27% of cases. In contrast, specialized vision models like BLIP2 and Llava showed preferences in 41.36% and 46.77% of cases, respectively. This framework highlights the potential of large multimodal models to outperform human diagnostics in certain tasks.
LoRA-LiteE: A Computationally Efficient Framework for Chatbot Preference-Tuning
Nov 15, 2024



Effective preference tuning is pivotal in aligning chatbot responses with human expectations, enhancing user satisfaction and engagement. Traditional approaches, notably Reinforcement Learning from Human Feedback (RLHF) as employed in advanced models like GPT-4, have demonstrated considerable success in this domain. However, RLHF methods are often computationally intensive and resource-demanding, limiting their scalability and accessibility for broader applications. To address these challenges, this study introduces LoRA-Lite Ensemble (LoRA-LiteE), an innovative framework that combines Supervised Fine-tuning (SFT) with Low-Rank Adaptation (LoRA) and Ensemble Learning techniques to effectively aggregate predictions of lightweight models, which aim to achieve a balance between the performance and computational cost. Utilizing the Chatbot Arena benchmark dataset, we conduct a comprehensive comparative analysis among our LoRA-LiteE model, corresponding base models at different scales, and GPT-4 trained with RLHF. Our empirical results demonstrate that the proposed LoRA-LiteE model achieves comparable performance to un-finetuned GPT-4 and outperforms the single larger-scale models under limited resource constraints. These findings highlight that our LoRA-LiteE provides a feasible and efficient methodology for human preference prediction in chatbot systems, enhancing scalability and accessibility, and thereby broadening the applicability of preference-tuned chatbots in resource-constrained environments.
Harnessing LLMs for API Interactions: A Framework for Classification and Synthetic Data Generation
Sep 18, 2024As Large Language Models (LLMs) advance in natural language processing, there is growing interest in leveraging their capabilities to simplify software interactions. In this paper, we propose a novel system that integrates LLMs for both classifying natural language inputs into corresponding API calls and automating the creation of sample datasets tailored to specific API functions. By classifying natural language commands, our system allows users to invoke complex software functionalities through simple inputs, improving interaction efficiency and lowering the barrier to software utilization. Our dataset generation approach also enables the efficient and systematic evaluation of different LLMs in classifying API calls, offering a practical tool for developers or business owners to assess the suitability of LLMs for customized API management. We conduct experiments on several prominent LLMs using generated sample datasets for various API functions. The results show that GPT-4 achieves a high classification accuracy of 0.996, while LLaMA-3-8B performs much worse at 0.759. These findings highlight the potential of LLMs to transform API management and validate the effectiveness of our system in guiding model testing and selection across diverse applications.