 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA-LiteE: A Computationally Efficient Framework for Chatbot Preference-Tuning
Nov 15, 2024



Effective preference tuning is pivotal in aligning chatbot responses with human expectations, enhancing user satisfaction and engagement. Traditional approaches, notably Reinforcement Learning from Human Feedback (RLHF) as employed in advanced models like GPT-4, have demonstrated considerable success in this domain. However, RLHF methods are often computationally intensive and resource-demanding, limiting their scalability and accessibility for broader applications. To address these challenges, this study introduces LoRA-Lite Ensemble (LoRA-LiteE), an innovative framework that combines Supervised Fine-tuning (SFT) with Low-Rank Adaptation (LoRA) and Ensemble Learning techniques to effectively aggregate predictions of lightweight models, which aim to achieve a balance between the performance and computational cost. Utilizing the Chatbot Arena benchmark dataset, we conduct a comprehensive comparative analysis among our LoRA-LiteE model, corresponding base models at different scales, and GPT-4 trained with RLHF. Our empirical results demonstrate that the proposed LoRA-LiteE model achieves comparable performance to un-finetuned GPT-4 and outperforms the single larger-scale models under limited resource constraints. These findings highlight that our LoRA-LiteE provides a feasible and efficient methodology for human preference prediction in chatbot systems, enhancing scalability and accessibility, and thereby broadening the applicability of preference-tuned chatbots in resource-constrained environments.
Harnessing LLMs for API Interactions: A Framework for Classification and Synthetic Data Generation
Sep 18, 2024As Large Language Models (LLMs) advance in natural language processing, there is growing interest in leveraging their capabilities to simplify software interactions. In this paper, we propose a novel system that integrates LLMs for both classifying natural language inputs into corresponding API calls and automating the creation of sample datasets tailored to specific API functions. By classifying natural language commands, our system allows users to invoke complex software functionalities through simple inputs, improving interaction efficiency and lowering the barrier to software utilization. Our dataset generation approach also enables the efficient and systematic evaluation of different LLMs in classifying API calls, offering a practical tool for developers or business owners to assess the suitability of LLMs for customized API management. We conduct experiments on several prominent LLMs using generated sample datasets for various API functions. The results show that GPT-4 achieves a high classification accuracy of 0.996, while LLaMA-3-8B performs much worse at 0.759. These findings highlight the potential of LLMs to transform API management and validate the effectiveness of our system in guiding model testing and selection across diverse applications.
Towards Resilient and Efficient LLMs: A Comparative Study of Efficiency, Performance, and Adversarial Robustness
Aug 08, 2024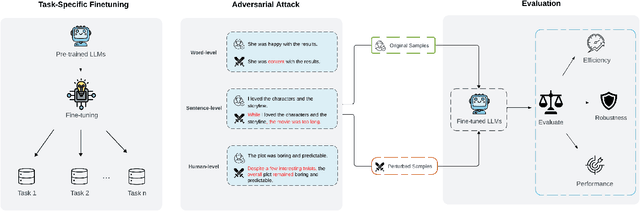

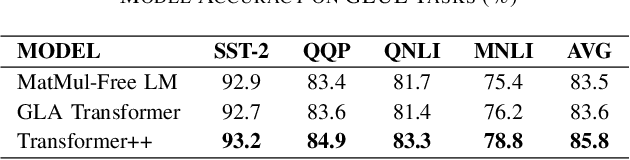

With the increasing demand for practical applications of Large Language Models (LLMs), many attention-efficient models have been developed to balance performance and computational cost. However, the adversarial robustness of these models remains under-explored. In this work, we design a framework to investigate the trade-off between efficiency, performance, and adversarial robustness of LLMs by comparing three prominent models with varying levels of complexity and efficiency -- Transformer++, Gated Linear Attention (GLA) Transformer, and MatMul-Free LM -- utilizing the GLUE and AdvGLUE datasets. The AdvGLUE dataset extends the GLUE dataset with adversarial samples designed to challenge model robustness. Our results show that while the GLA Transformer and MatMul-Free LM achieve slightly lower accuracy on GLUE tasks, they demonstrate higher efficiency and either superior or comparative robustness on AdvGLUE tasks compared to Transformer++ across different attack levels. These findings highlight the potential of simplified architectures to achieve a compelling balance between efficiency, performance, and adversarial robustness, offering valuable insights for applications where resource constraints and resilience to adversarial attacks are critical.