 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Resilient and Efficient LLMs: A Comparative Study of Efficiency, Performance, and Adversarial Robustness
Paper and Code
Aug 08, 2024

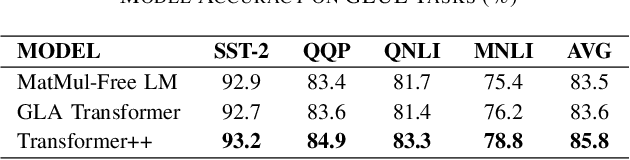

With the increasing demand for practical applications of Large Language Models (LLMs), many attention-efficient models have been developed to balance performance and computational cost. However, the adversarial robustness of these models remains under-explored. In this work, we design a framework to investigate the trade-off between efficiency, performance, and adversarial robustness of LLMs by comparing three prominent models with varying levels of complexity and efficiency -- Transformer++, Gated Linear Attention (GLA) Transformer, and MatMul-Free LM -- utilizing the GLUE and AdvGLUE datasets. The AdvGLUE dataset extends the GLUE dataset with adversarial samples designed to challenge model robustness. Our results show that while the GLA Transformer and MatMul-Free LM achieve slightly lower accuracy on GLUE tasks, they demonstrate higher efficiency and either superior or comparative robustness on AdvGLUE tasks compared to Transformer++ across different attack levels. These findings highlight the potential of simplified architectures to achieve a compelling balance between efficiency, performance, and adversarial robustness, offering valuable insights for applications where resource constraints and resilience to adversarial attacks are critical.