 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODE: Open-Set Evaluation of Hallucinations in Multimodal Large Language Models
Sep 14, 2024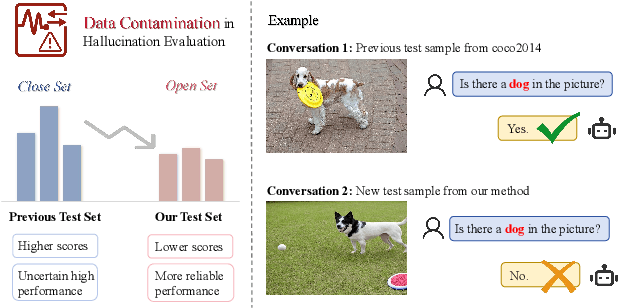

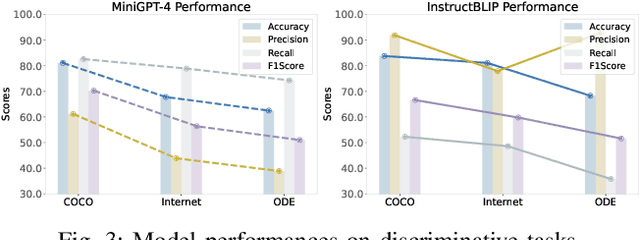

Hallucination poses a significant challenge for multimodal large language models (MLLMs). However, existing benchmarks for evaluating hallucinations are static, which can lead to potential data contamination. This paper introduces ODE, an open-set, dynamic protocol for evaluating object existence hallucinations in MLLMs. Our framework employs graph structures to model associations between real-word concepts and generates novel samples for both general and domain-specific scenarios. The dynamic combination of concepts, along with various combination principles, ensures a broad sample distribution. Experimental results show that MLLMs exhibit higher hallucination rates with ODE-generated samples, effectively avoiding data contamination. Moreover, these samples can also be used for fine-tuning to improve MLLM performance on existing benchmarks.
Prescribing the Right Remedy: Mitigating Hallucinations in Large Vision-Language Models via Targeted Instruction Tuning
Apr 16, 2024



Despite achieving outstanding performance on various cross-modal tasks, current large vision-language models (LVLMs) still suffer from hallucination issues, manifesting as inconsistencies between their generated responses and the corresponding images. Prior research has implicated that the low quality of instruction data, particularly the skewed balance between positive and negative samples, is a significant contributor to model hallucinations. Recently, researchers have proposed high-quality instruction datasets, such as LRV-Instruction, to mitigate model hallucination. Nonetheless, our investigation reveals that hallucinatory concepts from different LVLMs exhibit specificity, i.e. the distribution of hallucinatory concepts varies significantly across models. Existing datasets did not consider the hallucination specificity of different models in the design processes, thereby diminishing their efficacy in mitigating model hallucination. In this paper, we propose a targeted instruction data generation framework named DFTG that tailored to the hallucination specificity of different models. Concretely, DFTG consists of two stages: hallucination diagnosis, which extracts the necessary information from the model's responses and images for hallucination diagnosis; and targeted data generation, which generates targeted instruction data based on diagnostic results. The experimental results on hallucination benchmarks demonstrate that the targeted instruction data generated by our method are more effective in mitigating hallucinations compared to previous datasets.
Echoes: Unsupervised Debiasing via Pseudo-bias Labeling in an Echo Chamber
May 06, 2023
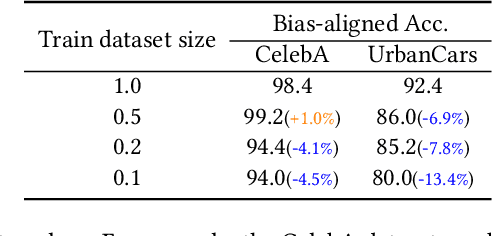


Neural networks often learn spurious correlations when exposed to biased training data, leading to poor performance on out-of-distribution data. A biased dataset can be divided, according to biased features, into bias-aligned samples (i.e., with biased features) and bias-conflicting samples (i.e., without biased features). Recent debiasing works typically assume that no bias label is available during the training phase, as obtaining such information is challenging and labor-intensive. Following this unsupervised assumption, existing methods usually train two models: a biased model specialized to learn biased features and a target model that uses information from the biased model for debiasing. This paper first presents experimental analyses revealing that the existing biased models overfit to bias-conflicting samples in the training data, which negatively impacts the debiasing performance of the target models. To address this issue, we propose a straightforward and effective method called \textit{Echoes}, which trains a biased model and a target model with a different strategy. We construct an "echo chamber" environment by reducing the weights of samples which are misclassified by the biased model, to ensure the biased model fully learns the biased features without overfitting to the bias-conflicting samples. The biased model then assigns lower weights on the bias-conflicting samples. Subsequently, we use the inverse of the sample weights of the biased model as the sample weights for training the target model. Experiments show that our approach achieves superior debiasing results compared to the existing baselines on both synthetic and real-world datasets.