 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust DNNs: An Taylor Expansion-Based Method for Generating Powerful Adversarial Examples
Jan 23, 2020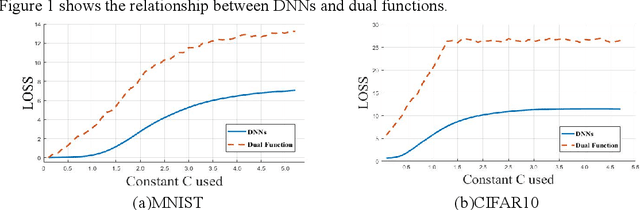
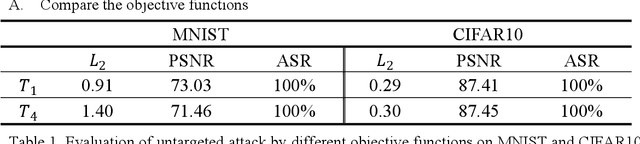
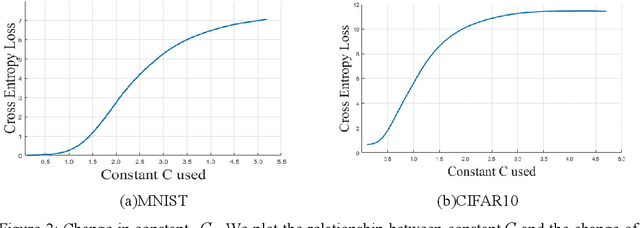
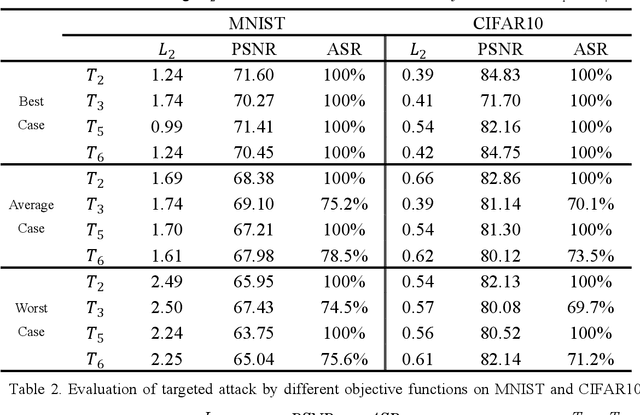
Although deep neural networks (DNNs) have achieved successful applications in many fields, they are vulnerable to adversarial examples. Adversarial training is one of the most effective methods to improve the robustness of DNNs, and it is generally considered as a minimax point problem that minimizes the loss function and maximizes the perturbation. Therefore, powerful adversarial examples can effectively simulate perturbation maximization to solve the minimax problem. In paper, a novel method was proposed to generate more powerful adversarial examples for robust adversarial training. The main idea is to approximates the output of DNNs in the input neighborhood by using the Taylor expansion, and then optimizes it by using the Lagrange multiplier method to generate adversarial examples. The experiment results show it can effectively improve the robust of DNNs trained with these powerful adversarial examples.
Spot Evasion Attacks: Adversarial Examples for License Plate Recognition Systems with Convolutional Neural Networks
Nov 28, 2019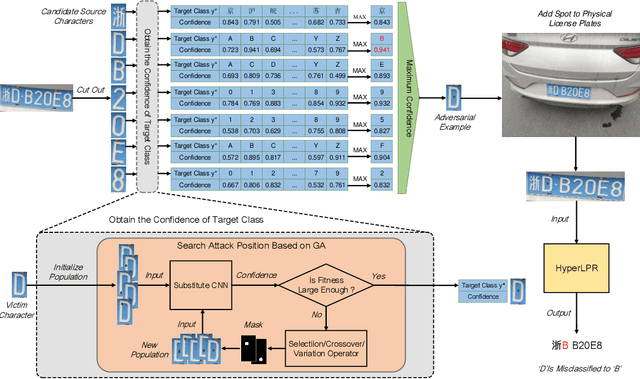
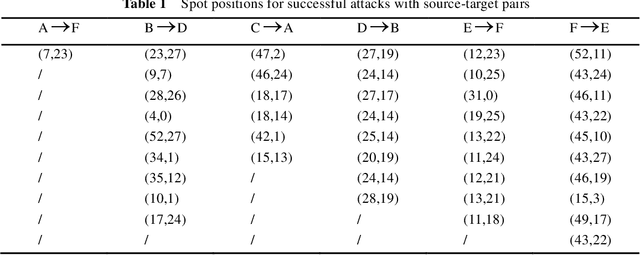
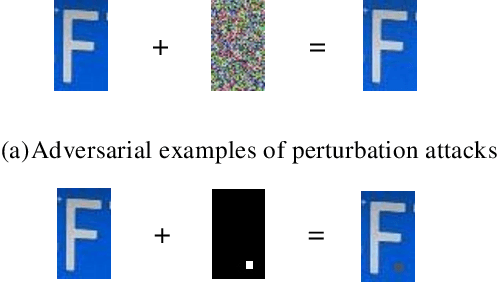
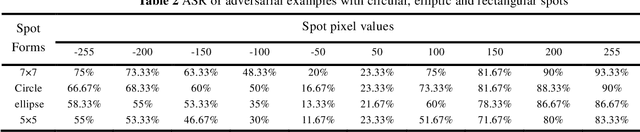
Recent studies have shown convolution neural networks (CNNs) for image recognition are vulnerable to evasion attacks with carefully manipulated adversarial examples. Previous work primarily focused on how to generate adversarial examples closed to source images, by introducing pixel-level perturbations into the whole or specific part of images. In this paper, we propose an evasion attack on CNN classifiers in the context of License Plate Recognition (LPR), which adds predetermined perturbations to specific regions of license plate images, simulating some sort of naturally formed spots (such as sludge, etc.). Therefore, the problem is modeled as an optimization process searching for optimal perturbation positions, which is different from previous work that consider pixel values as decision variables. Notice that this is a complex nonlinear optimization problem, and we use a genetic-algorithm based approach to obtain optimal perturbation positions. In experiments, we use the proposed algorithm to generate various adversarial examples in the form of rectangle, circle, ellipse and spots cluster. Experimental results show that these adversarial examples are almost ignored by human eyes, but can fool HyperLPR with high attack success rate over 93%. Therefore, we believe that this kind of spot evasion attacks would pose a great threat to current LPR systems, and needs to be investigated further by the security community.