 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopo4D: Topology-Preserving Gaussian Splatting for High-Fidelity 4D Head Capture
Jun 01, 20244D head capture aims to generate dynamic topological meshes and corresponding texture maps from videos, which is widely utilized in movies and games for its ability to simulate facial muscle movements and recover dynamic textures in pore-squeezing. The industry often adopts the method involving multi-view stereo and non-rigid alignment. However, this approach is prone to errors and heavily reliant on time-consuming manual processing by artists. To simplify this process, we propose Topo4D, a novel framework for automatic geometry and texture generation, which optimizes densely aligned 4D heads and 8K texture maps directly from calibrated multi-view time-series images. Specifically, we first represent the time-series faces as a set of dynamic 3D Gaussians with fixed topology in which the Gaussian centers are bound to the mesh vertices. Afterward, we perform alternative geometry and texture optimization frame-by-frame for high-quality geometry and texture learning while maintaining temporal topology stability. Finally, we can extract dynamic facial meshes in regular wiring arrangement and high-fidelity textures with pore-level details from the learned Gaussians. Extensive experiments show that our method achieves superior results than the current SOTA face reconstruction methods both in the quality of meshes and textures. Project page: https://xuanchenli.github.io/Topo4D/.
Improving the Robustness of Reinforcement Learning Policies with $\mathcal{L}_{1}$ Adaptive Control
Jan 03, 2022

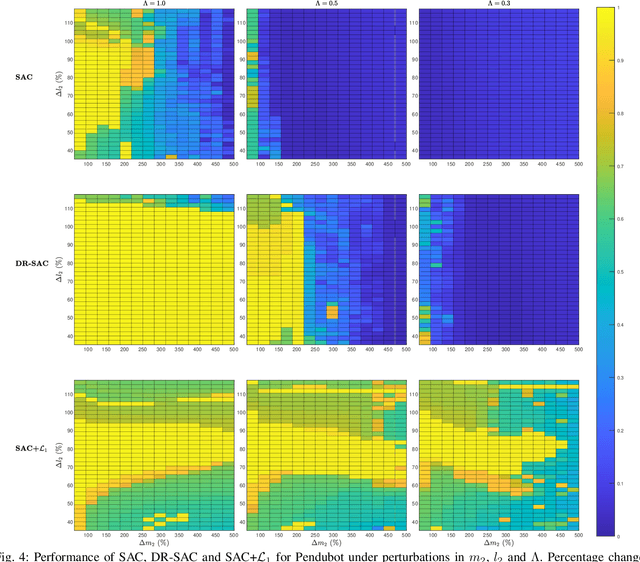

A reinforcement learning (RL) control policy trained in a nominal environment could fail in a new/perturbed environment due to the existence of dynamic variations. For controlling systems with continuous state and action spaces, we propose an add-on approach to robustifying a pre-trained RLpolicy by augmenting it with an $\mathcal{L}_{1}$ adaptive controller ($ \mathcal{L}_{1}$AC). Leveraging the capability of an $\mathcal{L}_{1}$AC for fast estimation and active compensation of dynamic variations, the proposed approach can improve the robustness of an RL policy which is trained either in a simulator or in the real world without consideration of a broad class of dynamic variations. Numerical and real-world experiments empirically demonstrate the efficacy of the proposed approach in robustifying RL policies trained using both model-free and model-based methods. A video for the experiments on a real Pendubot setup is availableathttps://youtu.be/xgOB9vpyUgE.