 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Robustness of Reinforcement Learning Policies with $\mathcal{L}_{1}$ Adaptive Control
Jan 03, 2022

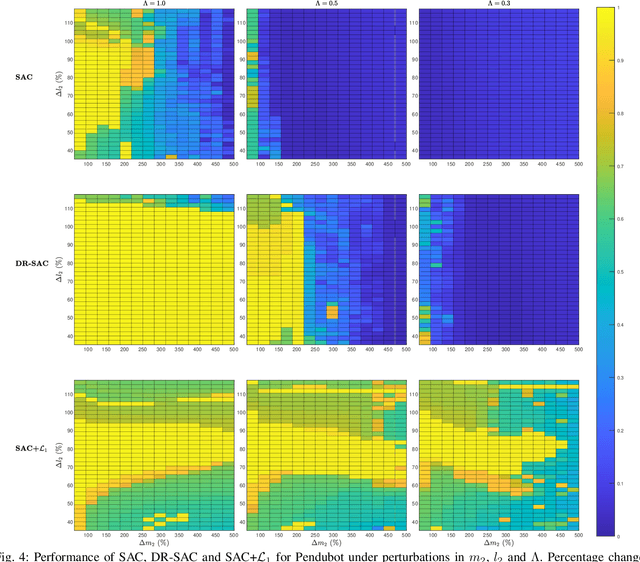

A reinforcement learning (RL) control policy trained in a nominal environment could fail in a new/perturbed environment due to the existence of dynamic variations. For controlling systems with continuous state and action spaces, we propose an add-on approach to robustifying a pre-trained RLpolicy by augmenting it with an $\mathcal{L}_{1}$ adaptive controller ($ \mathcal{L}_{1}$AC). Leveraging the capability of an $\mathcal{L}_{1}$AC for fast estimation and active compensation of dynamic variations, the proposed approach can improve the robustness of an RL policy which is trained either in a simulator or in the real world without consideration of a broad class of dynamic variations. Numerical and real-world experiments empirically demonstrate the efficacy of the proposed approach in robustifying RL policies trained using both model-free and model-based methods. A video for the experiments on a real Pendubot setup is availableathttps://youtu.be/xgOB9vpyUgE.