 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagonal RNNs in Symbolic Music Modeling
Apr 19, 2017
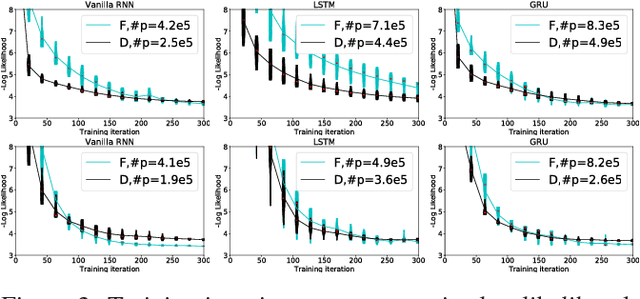
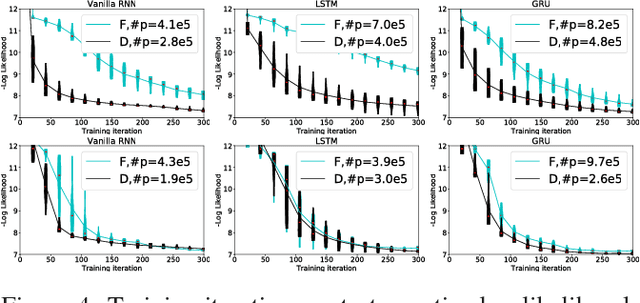
In this paper, we propose a new Recurrent Neural Network (RNN) architecture. The novelty is simple: We use diagonal recurrent matrices instead of full. This results in better test likelihood and faster convergence compared to regular full RNNs in most of our experiments. We show the benefits of using diagonal recurrent matrices with popularly used LSTM and GRU architectures as well as with the vanilla RNN architecture, on four standard symbolic music datasets.
A Dictionary Learning Approach for Factorial Gaussian Models
Aug 18, 2015

In this paper, we develop a parameter estimation method for factorially parametrized models such as Factorial Gaussian Mixture Model and Factorial Hidden Markov Model. Our contributions are two-fold. First, we show that the emission matrix of the standard Factorial Model is unidentifiable even if the true assignment matrix is known. Secondly, we address the issue of identifiability by making a one component sharing assumption and derive a parameter learning algorithm for this case. Our approach is based on a dictionary learning problem of the form $X = O R$, where the goal is to learn the dictionary $O$ given the data matrix $X$. We argue that due to the specific structure of the activation matrix $R$ in the shared component factorial mixture model, and an incoherence assumption on the shared component, it is possible to extract the columns of the $O$ matrix without the need for alternating between the estimation of $O$ and $R$.