Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagonal RNNs in Symbolic Music Modeling
Paper and Code

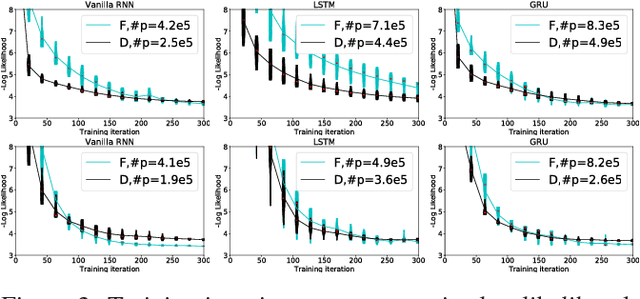
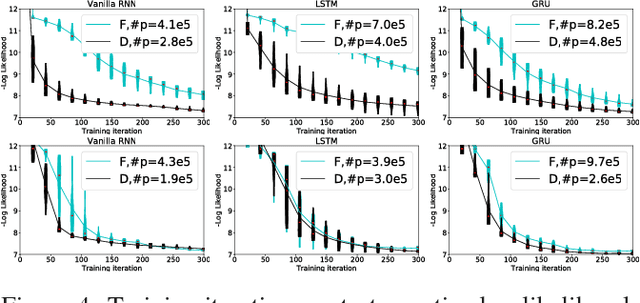
In this paper, we propose a new Recurrent Neural Network (RNN) architecture. The novelty is simple: We use diagonal recurrent matrices instead of full. This results in better test likelihood and faster convergence compared to regular full RNNs in most of our experiments. We show the benefits of using diagonal recurrent matrices with popularly used LSTM and GRU architectures as well as with the vanilla RNN architecture, on four standard symbolic music datasets.
* Submitted to Waspaa 2017
View paper on