 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEIC: Universal and Multilingual Named Entity Recognition with Large Language Models
Sep 18, 2024

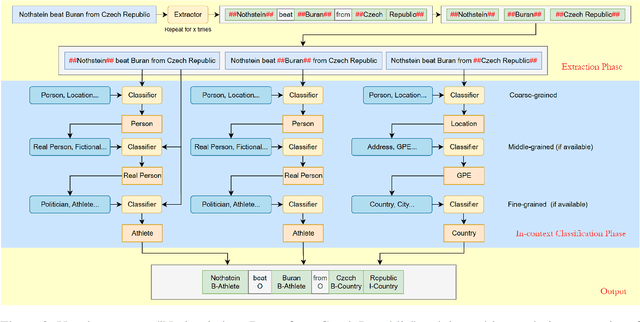

Large Language Models (LLMs) have supplanted traditional methods in numerous natural language processing tasks. Nonetheless, in Named Entity Recognition (NER), existing LLM-based methods underperform compared to baselines and require significantly more computational resources, limiting their application. In this paper, we introduce the task of generation-based extraction and in-context classification (GEIC), designed to leverage LLMs' prior knowledge and self-attention mechanisms for NER tasks. We then propose CascadeNER, a universal and multilingual GEIC framework for few-shot and zero-shot NER. CascadeNER employs model cascading to utilize two small-parameter LLMs to extract and classify independently, reducing resource consumption while enhancing accuracy. We also introduce AnythingNER, the first NER dataset specifically designed for LLMs, including 8 languages, 155 entity types and a novel dynamic categorization system. Experiments show that CascadeNER achieves state-of-the-art performance on low-resource and fine-grained scenarios, including CrossNER and FewNERD. Our work is openly accessible.
VersusDebias: Universal Zero-Shot Debiasing for Text-to-Image Models via SLM-Based Prompt Engineering and Generative Adversary
Jul 28, 2024



With the rapid development of Text-to-Image models, biases in human image generation against demographic groups social attract more and more concerns. Existing methods are designed based on certain models with fixed prompts, unable to accommodate the trend of high-speed updating of Text-to-Image (T2I) models and variable prompts in practical scenes. Additionally, they fail to consider the possibility of hallucinations, leading to deviations between expected and actual results. To address this issue, we introduce VersusDebias, a novel and universal debiasing framework for biases in T2I models, consisting of one generative adversarial mechanism (GAM) and one debiasing generation mechanism using a small language model (SLM). The self-adaptive GAM generates specialized attribute arrays for each prompts for diminishing the influence of hallucinations from T2I models. The SLM uses prompt engineering to generate debiased prompts for the T2I model, providing zero-shot debiasing ability and custom optimization for different models. Extensive experiments demonstrate VersusDebias's capability to rectify biases on arbitrary models across multiple protected attributes simultaneously, including gender, race, and age. Furthermore, VersusDebias outperforms existing methods in both zero-shot and few-shot situations, illustrating its extraordinary utility. Our work is openly accessible to the research community to ensure the reproducibility.
BIGbench: A Unified Benchmark for Social Bias in Text-to-Image Generative Models Based on Multi-modal LLM
Jul 23, 2024



Text-to-Image (T2I) generative models are becoming more crucial in terms of their ability to generate complex and high-quality images, which also raises concerns about the social biases in their outputs, especially in human generation. Sociological research has established systematic classifications of bias; however, existing research of T2I models often conflates different types of bias, hindering the progress of these methods. In this paper, we introduce BIGbench, a unified benchmark for Biases of Image Generation with a well-designed dataset. In contrast to existing benchmarks, BIGbench classifies and evaluates complex biases into four dimensions: manifestation of bias, visibility of bias, acquired attributes, and protected attributes. Additionally, BIGbench applies advanced multi-modal large language models (MLLM), achieving fully automated evaluation while maintaining high accuracy. We apply BIGbench to evaluate eight recent general T2I models and three debiased methods. We also conduct human evaluation, whose results demonstrated the effectiveness of BIGbench in aligning images and identifying various biases. Besides, our study also revealed new research directions about biases, including the side-effect of irrelevant protected attributes and distillation. Our dataset and benchmark is openly accessible to the research community to ensure the reproducibility.