 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Hashing based on Energy Minimization
Dec 02, 2017
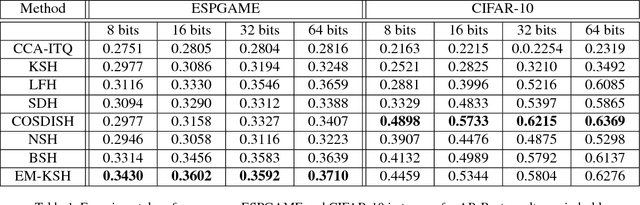
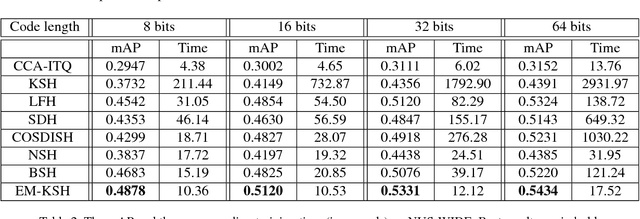
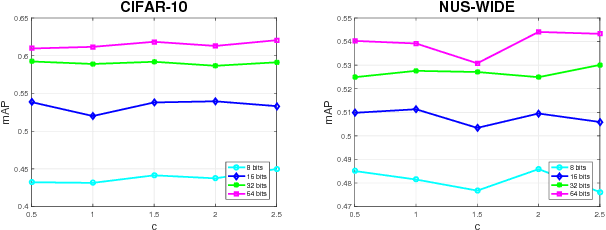
Recently, supervised hashing methods have attracted much attention since they can optimize retrieval speed and storage cost while preserving semantic information. Because hashing codes learning is NP-hard, many methods resort to some form of relaxation technique. But the performance of these methods can easily deteriorate due to the relaxation. Luckily, many supervised hashing formulations can be viewed as energy functions, hence solving hashing codes is equivalent to learning marginals in the corresponding conditional random field (CRF). By minimizing the KL divergence between a fully factorized distribution and the Gibbs distribution of this CRF, a set of consistency equations can be obtained, but updating them in parallel may not yield a local optimum since the variational lower bound is not guaranteed to increase. In this paper, we use a linear approximation of the sigmoid function to convert these consistency equations to linear systems, which have a closed-form solution. By applying this novel technique to two classical hashing formulations KSH and SPLH, we obtain two new methods called EM (energy minimizing based)-KSH and EM-SPLH. Experimental results on three datasets show the superiority of our methods.