 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Generative Data-Free Knowledge Distillation based on Attention Transfer
Dec 31, 2021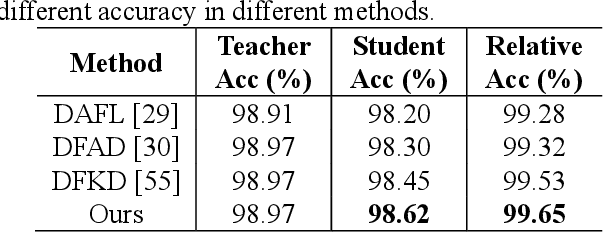

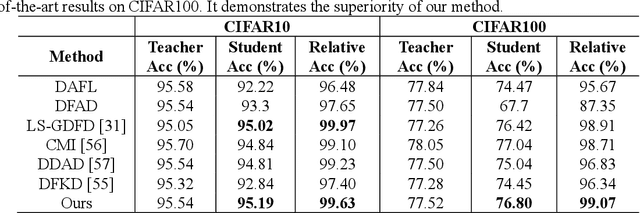

Knowledge distillation has made remarkable achievements in model compression. However, most existing methods demand original training data, while real data in practice are often unavailable due to privacy, security and transmission limitation. To address this problem, we propose a conditional generative data-free knowledge distillation (CGDD) framework to train efficient portable network without any real data. In this framework, except using the knowledge extracted from teacher model, we introduce preset labels as additional auxiliary information to train the generator. Then, the trained generator can produce meaningful training samples of specified category as required. In order to promote distillation process, except using conventional distillation loss, we treat preset label as ground truth label so that student network is directly supervised by the category of synthetic training sample. Moreover, we force student network to mimic the attention maps of teacher model and further improve its performance. To verify the superiority of our method, we design a new evaluation metric is called as relative accuracy to directly compare the effectiveness of different distillation methods. Trained portable network learned with proposed data-free distillation method obtains 99.63%, 99.07% and 99.84% relative accuracy on CIFAR10, CIFAR100 and Caltech101, respectively. The experimental results demonstrate the superiority of proposed method.