 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-based Video Segmentation for Human Head and Shoulders
Apr 20, 2021
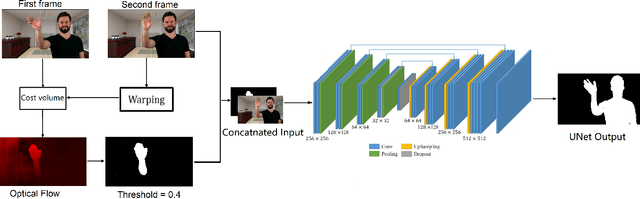
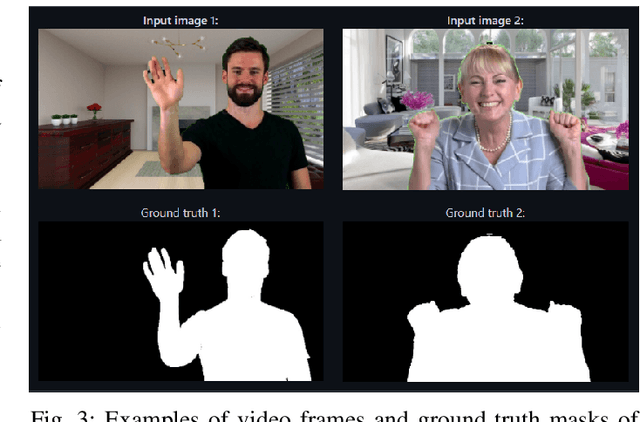

Video segmentation for the human head and shoulders is essential in creating elegant media for videoconferencing and virtual reality applications. The main challenge is to process high-quality background subtraction in a real-time manner and address the segmentation issues under motion blurs, e.g., shaking the head or waving hands during conference video. To overcome the motion blur problem in video segmentation, we propose a novel flow-based encoder-decoder network (FUNet) that combines both traditional Horn-Schunck optical-flow estimation technique and convolutional neural networks to perform robust real-time video segmentation. We also introduce a video and image segmentation dataset: ConferenceVideoSegmentationDataset. Code and pre-trained models are available on our GitHub repository: \url{https://github.com/kuangzijian/Flow-Based-Video-Matting}.
A Survey of Multimedia Technologies and Robust Algorithms
Mar 26, 2021Multimedia technologies are now more practical and deployable in real life, and the algorithms are widely used in various researching areas such as deep learning, signal processing, haptics, computer vision, robotics, and medical multimedia processing. This survey provides an overview of multimedia technologies and robust algorithms in multimedia data processing, medical multimedia processing, human facial expression tracking and pose recognition, and multimedia in education and training. This survey will also analyze and propose a future research direction based on the overview of current robust algorithms and multimedia technologies. We want to thank the research and previous work done by the Multimedia Research Centre (MRC), the University of Alberta, which is the inspiration and starting point for future research.
Computer Vision and Normalizing Flow Based Defect Detection
Dec 12, 2020


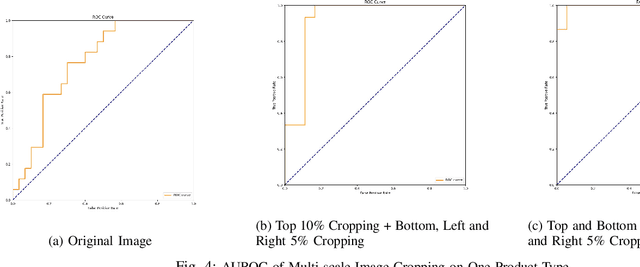
Surface defect detection is essential and necessary for controlling the qualities of the products during manufacturing. The challenges in this complex task include: 1) collecting defective samples and manually labeling for training is time-consuming; 2) the defects' characteristics are difficult to define as new types of defect can happen all the time; 3) and the real-world product images contain lots of background noise. In this paper, we present a two-stage defect detection network based on the object detection model YOLO, and the normalizing flow-based defect detection model DifferNet. Our model has high robustness and performance on defect detection using real-world video clips taken from a production line monitoring system. The normalizing flow-based anomaly detection model only requires a small number of good samples for training and then perform defect detection on the product images detected by YOLO. The model we invent employs two novel strategies: 1) a two-stage network using YOLO and a normalizing flow-based model to perform product defect detection, 2) multi-scale image transformations are implemented to solve the issue product image cropped by YOLO includes many background noise. Besides, extensive experiments are conducted on a new dataset collected from the real-world factory production line. We demonstrate that our proposed model can learn on a small number of defect-free samples of single or multiple product types. The dataset will also be made public to encourage further studies and research in surface defect detection.
Video Understanding based on Human Action and Group Activity Recognition
Oct 24, 2020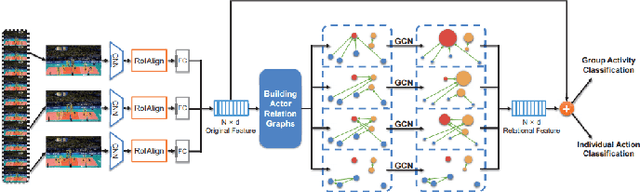


A lot of previous work, such as video captioning, has shown promising performance in producing general video understanding. However, it is still challenging to generate a fine-grained description of human actions and their interactions using state-of-the-art video captioning techniques. The detailed description of human actions and group activities is essential information, which can be used in real-time CCTV video surveillance, health care, sports video analysis, etc. In this study, we will propose and improve the video understanding method based on the Group Activity Recognition model by learning Actor Relation Graph (ARG).We will enhance the functionality and the performance of the ARG based model to perform a better video understanding by applying approaches such as increasing human object detection accuracy with YOLO, increasing process speed by reducing the input image size, and applying ResNet in the CNN layer.We will also introduce a visualization model that will visualize each input video frame with predicted bounding boxes on each human object and predicted "video captioning" to describe each individual's action and their collective activity.