 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Understanding based on Human Action and Group Activity Recognition
Paper and Code
Oct 24, 2020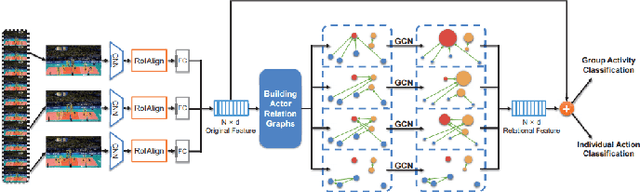


A lot of previous work, such as video captioning, has shown promising performance in producing general video understanding. However, it is still challenging to generate a fine-grained description of human actions and their interactions using state-of-the-art video captioning techniques. The detailed description of human actions and group activities is essential information, which can be used in real-time CCTV video surveillance, health care, sports video analysis, etc. In this study, we will propose and improve the video understanding method based on the Group Activity Recognition model by learning Actor Relation Graph (ARG).We will enhance the functionality and the performance of the ARG based model to perform a better video understanding by applying approaches such as increasing human object detection accuracy with YOLO, increasing process speed by reducing the input image size, and applying ResNet in the CNN layer.We will also introduce a visualization model that will visualize each input video frame with predicted bounding boxes on each human object and predicted "video captioning" to describe each individual's action and their collective activity.