 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharting the Future: Using Chart Question-Answering for Scalable Evaluation of LLM-Driven Data Visualizations
Sep 27, 2024



We propose a novel framework that leverages Visual Question Answering (VQA) models to automate the evaluation of LLM-generated data visualizations. Traditional evaluation methods often rely on human judgment, which is costly and unscalable, or focus solely on data accuracy, neglecting the effectiveness of visual communication. By employing VQA models, we assess data representation quality and the general communicative clarity of charts. Experiments were conducted using two leading VQA benchmark datasets, ChartQA and PlotQA, with visualizations generated by OpenAI's GPT-3.5 Turbo and Meta's Llama 3.1 70B-Instruct models. Our results indicate that LLM-generated charts do not match the accuracy of the original non-LLM-generated charts based on VQA performance measures. Moreover, while our results demonstrate that few-shot prompting significantly boosts the accuracy of chart generation, considerable progress remains to be made before LLMs can fully match the precision of human-generated graphs. This underscores the importance of our work, which expedites the research process by enabling rapid iteration without the need for human annotation, thus accelerating advancements in this field.
Improving Expert Radiology Report Summarization by Prompting Large Language Models with a Layperson Summary
Jun 20, 2024



Radiology report summarization (RRS) is crucial for patient care, requiring concise "Impressions" from detailed "Findings." This paper introduces a novel prompting strategy to enhance RRS by first generating a layperson summary. This approach normalizes key observations and simplifies complex information using non-expert communication techniques inspired by doctor-patient interactions. Combined with few-shot in-context learning, this method improves the model's ability to link general terms to specific findings. We evaluate this approach on the MIMIC-CXR, CheXpert, and MIMIC-III datasets, benchmarking it against 7B/8B parameter state-of-the-art open-source large language models (LLMs) like Meta-Llama-3-8B-Instruct. Our results demonstrate improvements in summarization accuracy and accessibility, particularly in out-of-domain tests, with improvements as high as 5% for some metrics.
BabyStories: Can Reinforcement Learning Teach Baby Language Models to Write Better Stories?
Oct 25, 2023



Language models have seen significant growth in the size of their corpus, leading to notable performance improvements. Yet, there has been limited progress in developing models that handle smaller, more human-like datasets. As part of the BabyLM shared task, this study explores the impact of reinforcement learning from human feedback (RLHF) on language models pretrained from scratch with a limited training corpus. Comparing two GPT-2 variants, the larger model performs better in storytelling tasks after RLHF fine-tuning. These findings suggest that RLHF techniques may be more advantageous for larger models due to their higher learning and adaptation capacity, though more experiments are needed to confirm this finding. These insights highlight the potential benefits of RLHF fine-tuning for language models within limited data, enhancing their ability to maintain narrative focus and coherence while adhering better to initial instructions in storytelling tasks. The code for this work is publicly at https://github.com/Zephyr1022/BabyStories-UTSA.
Bike Frames: Understanding the Implicit Portrayal of Cyclists in the News
Jan 15, 2023Increasing the number of cyclists, whether for general transport or recreation, can provide health improvements and reduce the environmental impact of vehicular transportation. However, the public's perception of cycling may be driven by the ideologies and reporting standards of news agencies. For instance, people may identify cyclists on the road as "dangerous" if news agencies overly report cycling accidents, limiting the number of people that cycle for transportation. Moreover, if fewer people cycle, there may be less funding from the government to invest in safe infrastructure. In this paper, we explore the perceived perception of cyclists within news headlines. To accomplish this, we introduce a new dataset, "Bike Frames", that can help provide insight into how headlines portray cyclists and help detect accident-related headlines. Next, we introduce a multi-task (MT) regularization approach that increases the detection accuracy of accident-related posts, demonstrating improvements over traditional MT frameworks. Finally, we compare and contrast the perceptions of cyclists with motorcyclist-related headlines to ground the findings with another related activity for both male- and female-related posts. Our findings show that general news websites are more likely to report accidents about cyclists than other events. Moreover, cyclist-specific websites are more likely to report about accidents than motorcycling-specific websites, even though there is more potential danger for motorcyclists. Finally, we show substantial differences in the reporting about male vs. female-related persons, e.g., more male-related cyclists headlines are related to accidents, but more female-related motorcycling headlines about accidents. WARNING: This paper contains descriptions of accidents and death.
A Marker-based Neural Network System for Extracting Social Determinants of Health
Dec 24, 2022



Objective. The impact of social determinants of health (SDoH) on patients' healthcare quality and the disparity is well-known. Many SDoH items are not coded in structured forms in electronic health records. These items are often captured in free-text clinical notes, but there are limited methods for automatically extracting them. We explore a multi-stage pipeline involving named entity recognition (NER), relation classification (RC), and text classification methods to extract SDoH information from clinical notes automatically. Materials and Methods. The study uses the N2C2 Shared Task data, which was collected from two sources of clinical notes: MIMIC-III and University of Washington Harborview Medical Centers. It contains 4480 social history sections with full annotation for twelve SDoHs. In order to handle the issue of overlapping entities, we developed a novel marker-based NER model. We used it in a multi-stage pipeline to extract SDoH information from clinical notes. Results. Our marker-based system outperformed the state-of-the-art span-based models at handling overlapping entities based on the overall Micro-F1 score performance. It also achieved state-of-the-art performance compared to the shared task methods. Conclusion. The major finding of this study is that the multi-stage pipeline effectively extracts SDoH information from clinical notes. This approach can potentially improve the understanding and tracking of SDoHs in clinical settings. However, error propagation may be an issue, and further research is needed to improve the extraction of entities with complex semantic meanings and low-resource entities using external knowledge.
A Comprehensive Study of Gender Bias in Chemical Named Entity Recognition Models
Dec 24, 2022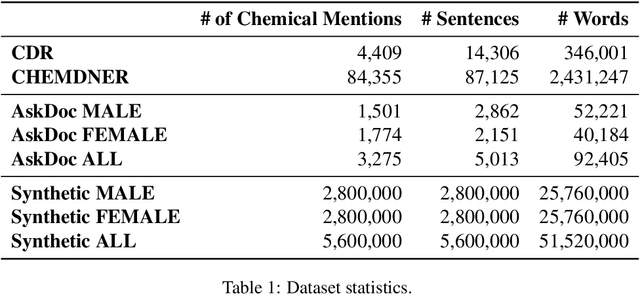
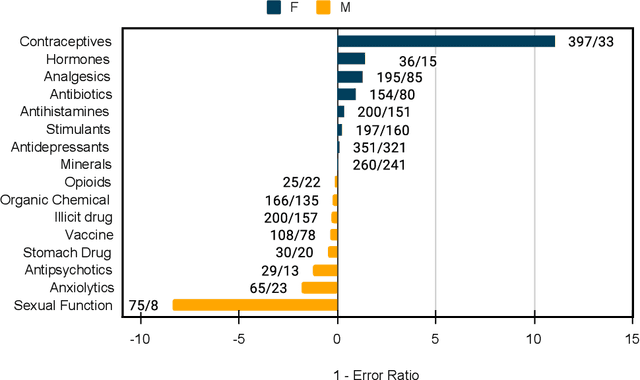


Objective. Chemical named entity recognition (NER) models have the potential to impact a wide range of downstream tasks, from identifying adverse drug reactions to general pharmacoepidemiology. However, it is unknown whether these models work the same for everyone. Performance disparities can potentially cause harm rather than the intended good. Hence, in this paper, we measure gender-related performance disparities of chemical NER systems. Materials and Methods. We develop a framework to measure gender bias in chemical NER models using synthetic data and a newly annotated dataset of over 92,405 words with self-identified gender information from Reddit. We applied and evaluated state-of-the-art biomedical NER models. Results. Our findings indicate that chemical NER models are biased. The results of the bias tests on the synthetic dataset and the real-world data multiple fairness issues. For example, for synthetic data, we find that female-related names are generally classified as chemicals, particularly in datasets containing many brand names rather than standard ones. For both datasets, we find consistent fairness issues resulting in substantial performance disparities between female- and male-related data. Discussion. Our study highlights the issue of biases in chemical NER models. For example, we find that many systems cannot detect contraceptives (e.g., birth control). Conclusion. Chemical NER models are biased and can be harmful to female-related groups. Therefore, practitioners should carefully consider the potential biases of these models and take steps to mitigate them.
UTSA NLP at SemEval-2022 Task 4: An Exploration of Simple Ensembles of Transformers, Convolutional, and Recurrent Neural Networks
Mar 28, 2022
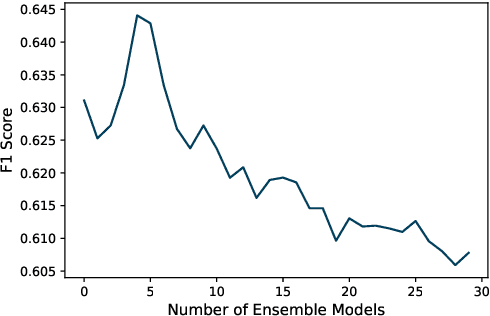

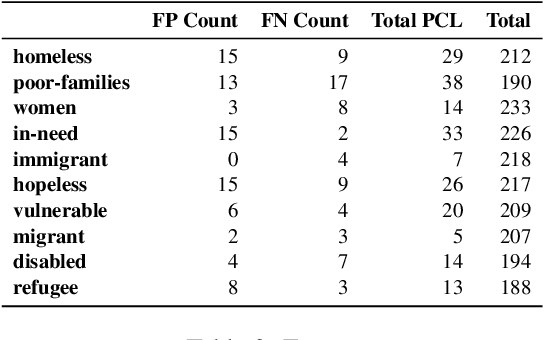
The act of appearing kind or helpful via the use of but having a feeling of superiority condescending and patronizing language can have have serious mental health implications to those that experience it. Thus, detecting this condescending and patronizing language online can be useful for online moderation systems. Thus, in this manuscript, we describe the system developed by Team UTSA SemEval-2022 Task 4, Detecting Patronizing and Condescending Language. Our approach explores the use of several deep learning architectures including RoBERTa, convolutions neural networks, and Bidirectional Long Short-Term Memory Networks. Furthermore, we explore simple and effective methods to create ensembles of neural network models. Overall, we experimented with several ensemble models and found that the a simple combination of five RoBERTa models achieved an F-score of .6441 on the development dataset and .5745 on the final test dataset. Finally, we also performed a comprehensive error analysis to better understand the limitations of the model and provide ideas for further research.
Turning Stocks into Memes: A Dataset for Understanding How Social Communities Can Drive Wall Street
Mar 16, 2022



Who actually expresses an intent to buy GameStop shares on Reddit? What convinces people to buy stocks? Are people convinced to support a coordinated plan to adversely impact Wall Street investors? Existing literature on understanding intent has mainly relied on surveys and self reporting; however there are limitations to these methodologies. Hence, in this paper, we develop an annotated dataset of communications centered on the GameStop phenomenon to analyze the subscriber intentions behaviors within the r/WallStreetBets community to buy (or not buy) stocks. Likewise, we curate a dataset to better understand how intent interacts with a user's general support towards the coordinated actions of the community for GameStop. Overall, our dataset can provide insight to social scientists on the persuasive power to buy into social movements online by adopting common language and narrative. WARNING: This paper contains offensive language that commonly appears on Reddit's r/WallStreetBets subreddit.