 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoes of Discord: Forecasting Hater Reactions to Counterspeech
Jan 27, 2025
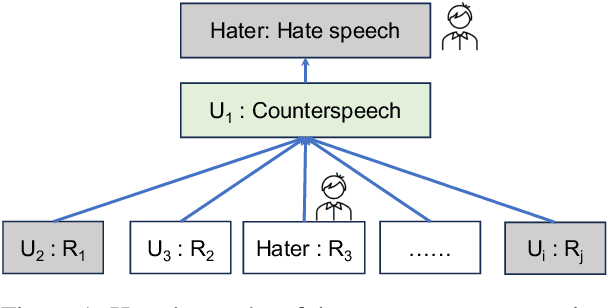
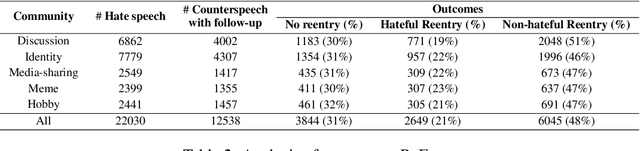

Hate speech (HS) erodes the inclusiveness of online users and propagates negativity and division. Counterspeech has been recognized as a way to mitigate the harmful consequences. While some research has investigated the impact of user-generated counterspeech on social media platforms, few have examined and modeled haters' reactions toward counterspeech, despite the immediate alteration of haters' attitudes being an important aspect of counterspeech. This study fills the gap by analyzing the impact of counterspeech from the hater's perspective, focusing on whether the counterspeech leads the hater to reenter the conversation and if the reentry is hateful. We compile the Reddit Echoes of Hate dataset (ReEco), which consists of triple-turn conversations featuring haters' reactions, to assess the impact of counterspeech. The linguistic analysis sheds insights on the language of counterspeech to hate eliciting different haters' reactions. Experimental results demonstrate that the 3-way classification model outperforms the two-stage reaction predictor, which first predicts reentry and then determines the reentry type. We conclude the study with an assessment showing the most common errors identified by the best-performing model.
Hate Cannot Drive out Hate: Forecasting Conversation Incivility following Replies to Hate Speech
Dec 08, 2023User-generated replies to hate speech are promising means to combat hatred, but questions about whether they can stop incivility in follow-up conversations linger. We argue that effective replies stop incivility from emerging in follow-up conversations - replies that elicit more incivility are counterproductive. This study introduces the task of predicting the incivility of conversations following replies to hate speech. We first propose a metric to measure conversation incivility based on the number of civil and uncivil comments as well as the unique authors involved in the discourse. Our metric approximates human judgments more accurately than previous metrics. We then use the metric to evaluate the outcomes of replies to hate speech. A linguistic analysis uncovers the differences in the language of replies that elicit follow-up conversations with high and low incivility. Experimental results show that forecasting incivility is challenging. We close with a qualitative analysis shedding light into the most common errors made by the best model.
Hate Speech and Counter Speech Detection: Conversational Context Does Matter
Jun 13, 2022
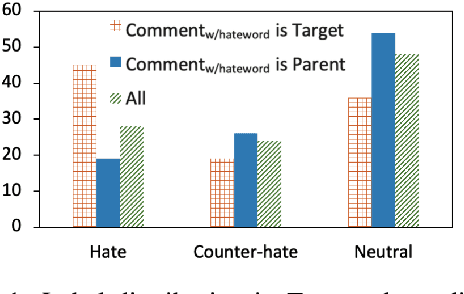
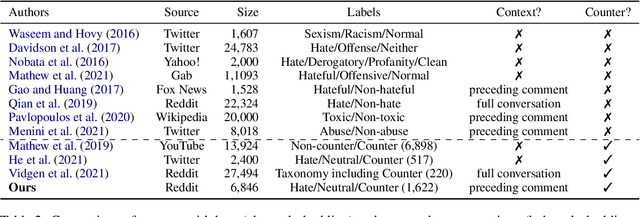
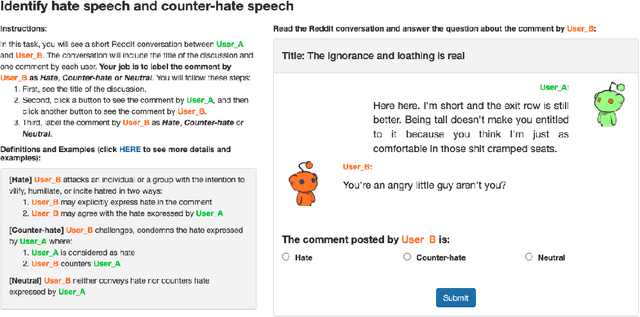
Hate speech is plaguing the cyberspace along with user-generated content. This paper investigates the role of conversational context in the annotation and detection of online hate and counter speech, where context is defined as the preceding comment in a conversation thread. We created a context-aware dataset for a 3-way classification task on Reddit comments: hate speech, counter speech, or neutral. Our analyses indicate that context is critical to identify hate and counter speech: human judgments change for most comments depending on whether we show annotators the context. A linguistic analysis draws insights into the language people use to express hate and counter speech. Experimental results show that neural networks obtain significantly better results if context is taken into account. We also present qualitative error analyses shedding light into (a) when and why context is beneficial and (b) the remaining errors made by our best model when context is taken into account.