 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior Knowledge Distillation Network for Face Super-Resolution
Sep 22, 2024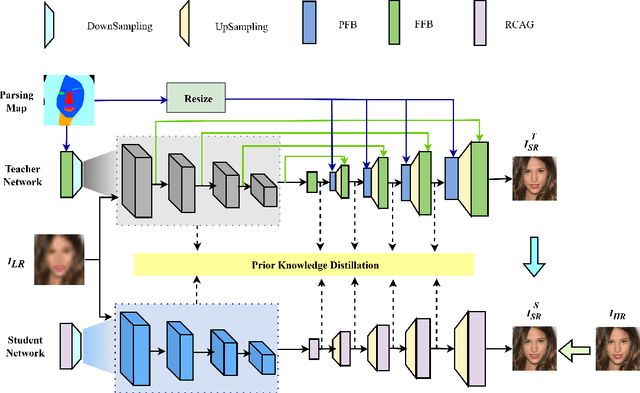
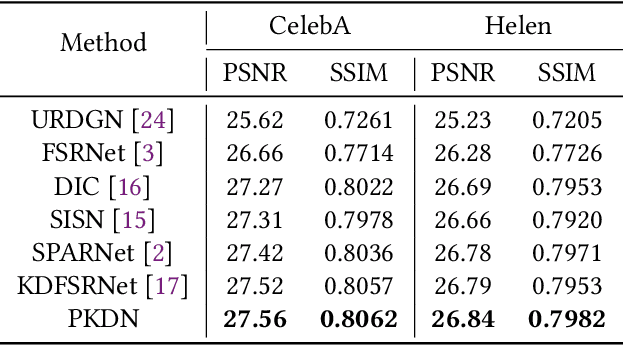
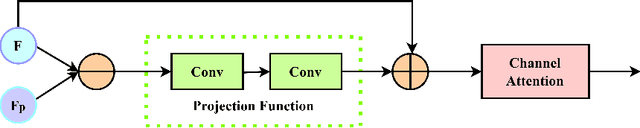
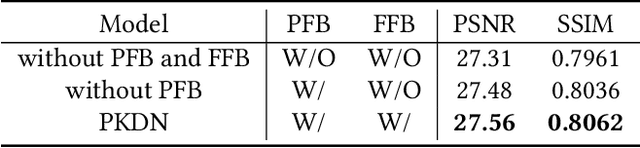
The purpose of face super-resolution (FSR) is to reconstruct high-resolution (HR) face images from low-resolution (LR) inputs. With the continuous advancement of deep learning technologies, contemporary prior-guided FSR methods initially estimate facial priors and then use this information to assist in the super-resolution reconstruction process. However, ensuring the accuracy of prior estimation remains challenging, and straightforward cascading and convolutional operations often fail to fully leverage prior knowledge. Inaccurate or insufficiently utilized prior information inevitably degrades FSR performance. To address this issue, we propose a prior knowledge distillation network (PKDN) for FSR, which involves transferring prior information from the teacher network to the student network. This approach enables the network to learn priors during the training stage while relying solely on low-resolution facial images during the testing stage, thus mitigating the adverse effects of prior estimation inaccuracies. Additionally, we incorporate robust attention mechanisms to design a parsing map fusion block that effectively utilizes prior information. To prevent feature loss, we retain multi-scale features during the feature extraction stage and employ them in the subsequent super-resolution reconstruction process. Experimental results on benchmark datasets demonstrate that our PKDN approach surpasses existing FSR methods in generating high-quality face images.