 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Feature-Label Dependence Using Gini Distance Statistics
Jun 05, 2019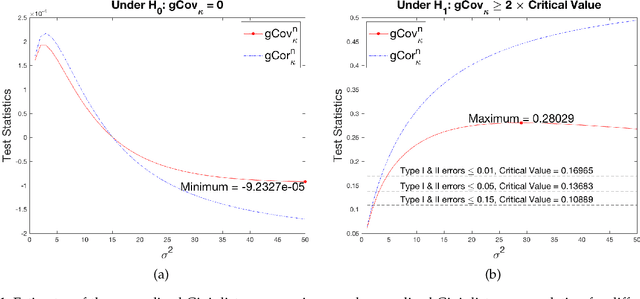

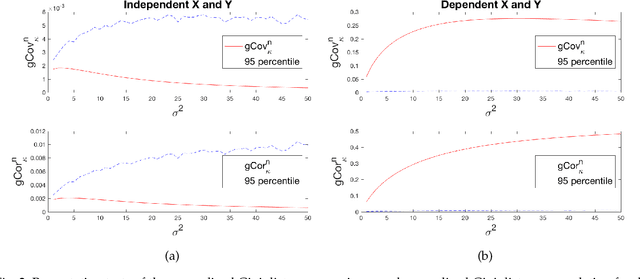
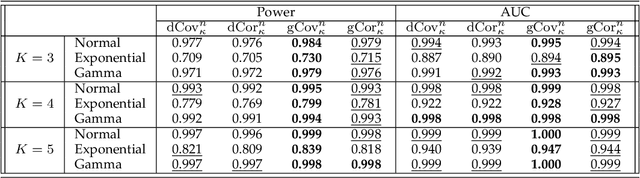
Identifying statistical dependence between the features and the label is a fundamental problem in supervised learning. This paper presents a framework for estimating dependence between numerical features and a categorical label using generalized Gini distance, an energy distance in reproducing kernel Hilbert spaces (RKHS). Two Gini distance based dependence measures are explored: Gini distance covariance and Gini distance correlation. Unlike Pearson covariance and correlation, which do not characterize independence, the above Gini distance based measures define dependence as well as independence of random variables. The test statistics are simple to calculate and do not require probability density estimation. Uniform convergence bounds and asymptotic bounds are derived for the test statistics. Comparisons with distance covariance statistics are provided. It is shown that Gini distance statistics converge faster than distance covariance statistics in the uniform convergence bounds, hence tighter upper bounds on both Type I and Type II errors. Moreover, the probability of Gini distance covariance statistic under-performing the distance covariance statistic in Type II error decreases to 0 exponentially with the increase of the sample size. Extensive experimental results are presented to demonstrate the performance of the proposed method.
Robust and Efficient Boosting Method using the Conditional Risk
Jun 21, 2018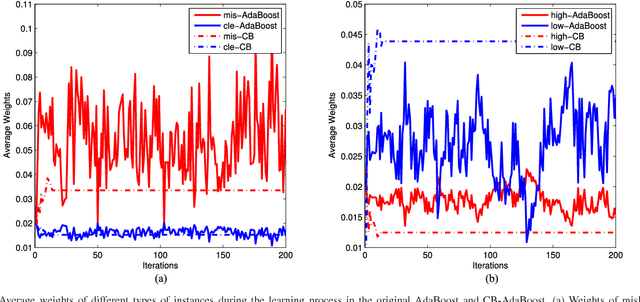
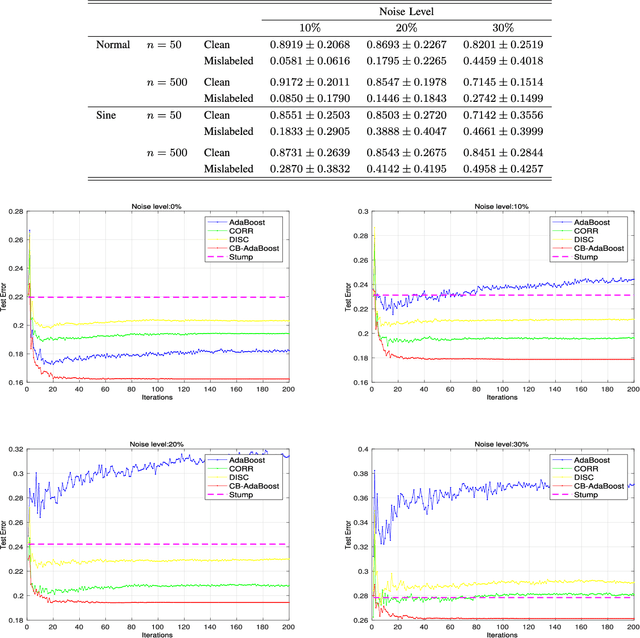
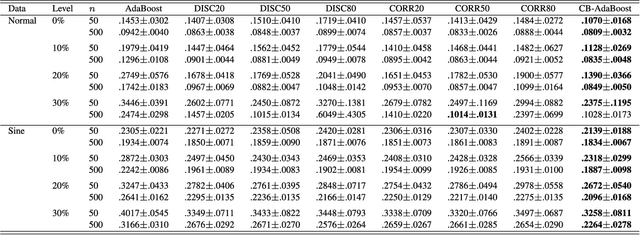
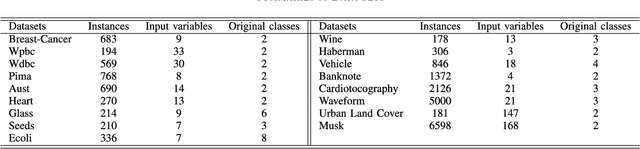
Well-known for its simplicity and effectiveness in classification, AdaBoost, however, suffers from overfitting when class-conditional distributions have significant overlap. Moreover, it is very sensitive to noise that appears in the labels. This article tackles the above limitations simultaneously via optimizing a modified loss function (i.e., the conditional risk). The proposed approach has the following two advantages. (1) It is able to directly take into account label uncertainty with an associated label confidence. (2) It introduces a "trustworthiness" measure on training samples via the Bayesian risk rule, and hence the resulting classifier tends to have finite sample performance that is superior to that of the original AdaBoost when there is a large overlap between class conditional distributions. Theoretical properties of the proposed method are investigated. Extensive experimental results using synthetic data and real-world data sets from UCI machine learning repository are provided. The empirical study shows the high competitiveness of the proposed method in predication accuracy and robustness when compared with the original AdaBoost and several existing robust AdaBoost algorithms.