 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection in Networked Bandits
Aug 27, 2025The nodes' interconnections on a social network often reflect their dependencies and information-sharing behaviors. Nevertheless, abnormal nodes, which significantly deviate from most of the network concerning patterns or behaviors, can lead to grave consequences. Therefore, it is imperative to design efficient online learning algorithms that robustly learn users' preferences while simultaneously detecting anomalies. We introduce a novel bandit algorithm to address this problem. Through network knowledge, the method characterizes the users' preferences and residuals of feature information. By learning and analyzing these preferences and residuals, it develops a personalized recommendation strategy for each user and simultaneously detects anomalies. We rigorously prove an upper bound on the regret of the proposed algorithm and experimentally compare it with several state-of-the-art collaborative contextual bandit algorithms on both synthetic and real-world datasets.
Distributed Management of Fluctuating Energy Resources in Dynamic Networked Systems
May 29, 2024Modern power systems integrate renewable distributed energy resources (DERs) as an environment-friendly enhancement to meet the ever-increasing demands. However, the inherent unreliability of renewable energy renders developing DER management algorithms imperative. We study the energy-sharing problem in a system consisting of several DERs. Each agent harvests and distributes renewable energy in its neighborhood to optimize the network's performance while minimizing energy waste. We model this problem as a bandit convex optimization problem with constraints that correspond to each node's limitations for energy production. We propose distributed decision-making policies to solve the formulated problem, where we utilize the notion of dynamic regret as the performance metric. We also include an adjustment strategy in our developed algorithm to reduce the constraint violations. Besides, we design a policy that deals with the non-stationary environment. Theoretical analysis shows the effectiveness of our proposed algorithm. Numerical experiments using a real-world dataset show superior performance of our proposal compared to state-of-the-art methods.
Distributed Consensus Algorithm for Decision-Making in Multi-agent Multi-armed Bandit
Jun 09, 2023



We study a structured multi-agent multi-armed bandit (MAMAB) problem in a dynamic environment. A graph reflects the information-sharing structure among agents, and the arms' reward distributions are piecewise-stationary with several unknown change points. The agents face the identical piecewise-stationary MAB problem. The goal is to develop a decision-making policy for the agents that minimizes the regret, which is the expected total loss of not playing the optimal arm at each time step. Our proposed solution, Restarted Bayesian Online Change Point Detection in Cooperative Upper Confidence Bound Algorithm (RBO-Coop-UCB), involves an efficient multi-agent UCB algorithm as its core enhanced with a Bayesian change point detector. We also develop a simple restart decision cooperation that improves decision-making. Theoretically, we establish that the expected group regret of RBO-Coop-UCB is upper bounded by $\mathcal{O}(KNM\log T + K\sqrt{MT\log T})$, where K is the number of agents, M is the number of arms, and T is the number of time steps. Numerical experiments on synthetic and real-world datasets demonstrate that our proposed method outperforms the state-of-the-art algorithms.
Cooperative Thresholded Lasso for Sparse Linear Bandit
May 30, 2023We present a novel approach to address the multi-agent sparse contextual linear bandit problem, in which the feature vectors have a high dimension $d$ whereas the reward function depends on only a limited set of features - precisely $s_0 \ll d$. Furthermore, the learning follows under information-sharing constraints. The proposed method employs Lasso regression for dimension reduction, allowing each agent to independently estimate an approximate set of main dimensions and share that information with others depending on the network's structure. The information is then aggregated through a specific process and shared with all agents. Each agent then resolves the problem with ridge regression focusing solely on the extracted dimensions. We represent algorithms for both a star-shaped network and a peer-to-peer network. The approaches effectively reduce communication costs while ensuring minimal cumulative regret per agent. Theoretically, we show that our proposed methods have a regret bound of order $\mathcal{O}(s_0 \log d + s_0 \sqrt{T})$ with high probability, where $T$ is the time horizon. To our best knowledge, it is the first algorithm that tackles row-wise distributed data in sparse linear bandits, achieving comparable performance compared to the state-of-the-art single and multi-agent methods. Besides, it is widely applicable to high-dimensional multi-agent problems where efficient feature extraction is critical for minimizing regret. To validate the effectiveness of our approach, we present experimental results on both synthetic and real-world datasets.
Distributed Task Management in the Heterogeneous Fog: A Socially Concave Bandit Game
Mar 28, 2022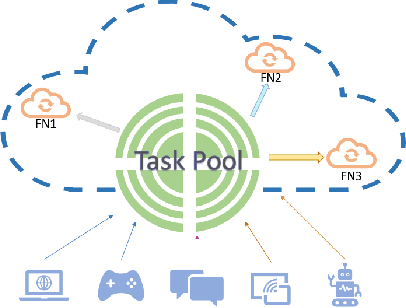
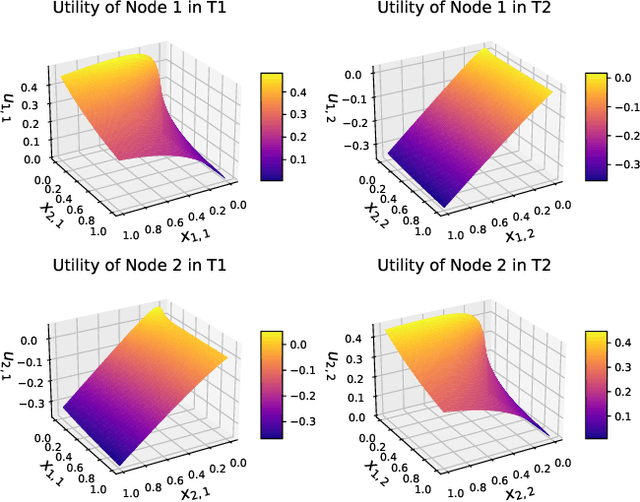
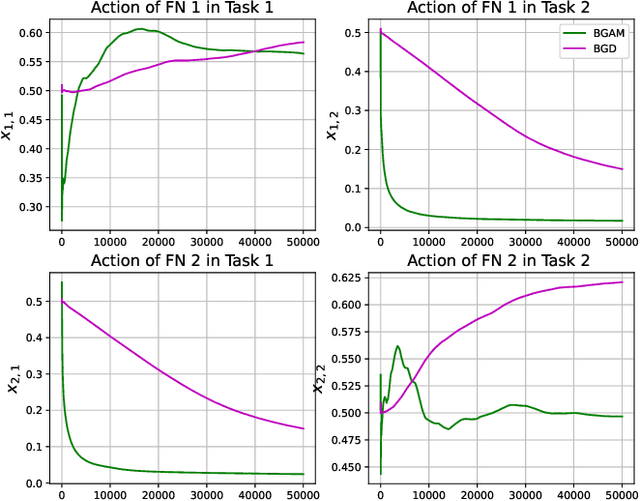

Fog computing has emerged as a potential solution to the explosive computational demand of mobile users. This potential mainly stems from the capacity of task offloading and allocation at the network edge, which reduces the delay and improves the quality of service. Despite the significant potential, optimizing the performance of a fog network is often challenging. In the fog architecture, the computing nodes are heterogeneous smart devices with distinct abilities and capacities, thereby, preferences. Besides, in an ultra-dense fog network with random task arrival, centralized control results in excessive overhead, and therefore, it is not feasible. We study a distributed task allocation problem in a heterogeneous fog computing network under uncertainty. We formulate the problem as a social-concave game, where the players attempt to minimize their regret on the path to Nash equilibrium. To solve the formulated problem, we develop two no-regret decision-making strategies. One strategy, namely bandit gradient ascent with momentum, is an online convex optimization algorithm with bandit feedback. The other strategy, Lipschitz Bandit with Initialization, is an EXP3 multi-armed bandit algorithm. We establish a regret bound for both strategies and analyze their convergence characteristics. Moreover, we compare the proposed strategies with a centralized allocation strategy named Learning with Linear Rewards. Theoretical and numerical analysis shows the superior performance of the proposed strategies for efficient task allocation compared to the state-of-the-art methods.