 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurbo-GoDec: Exploiting the Cluster Sparsity Prior for Hyperspectral Anomaly Detection
Jan 18, 2026As a key task in hyperspectral image processing, hyperspectral anomaly detection has garnered significant attention and undergone extensive research. Existing methods primarily relt on two prior assumption: low-rank background and sparse anomaly, along with additional spatial assumptions of the background. However, most methods only utilize the sparsity prior assumption for anomalies and rarely expand on this hypothesis. From observations of hyperspectral images, we find that anomalous pixels exhibit certain spatial distribution characteristics: they often manifest as small, clustered groups in space, which we refer to as cluster sparsity of anomalies. Then, we combined the cluster sparsity prior with the classical GoDec algorithm, incorporating the cluster sparsity prior into the S-step of GoDec. This resulted in a new hyperspectral anomaly detection method, which we called Turbo-GoDec. In this approach, we modeled the cluster sparsity prior of anomalies using a Markov random field and computed the marginal probabilities of anomalies through message passing on a factor graph. Locations with high anomalous probabilities were treated as the sparse component in the Turbo-GoDec. Experiments are conducted on three real hyperspectral image (HSI) datasets which demonstrate the superior performance of the proposed Turbo-GoDec method in detecting small-size anomalies comparing with the vanilla GoDec (LSMAD) and state-of-the-art anomaly detection methods. The code is available at https://github.com/jiahuisheng/Turbo-GoDec.
Utilizing the Score of Data Distribution for Hyperspectral Anomaly Detection
Jan 18, 2026Hyperspectral images (HSIs) are a type of image that contains abundant spectral information. As a type of real-world data, the high-dimensional spectra in hyperspectral images are actually determined by only a few factors, such as chemical composition and illumination. Thus, spectra in hyperspectral images are highly likely to satisfy the manifold hypothesis. Based on the hyperspectral manifold hypothesis, we propose a novel hyperspectral anomaly detection method (named ScoreAD) that leverages the time-dependent gradient field of the data distribution (i.e., the score), as learned by a score-based generative model (SGM). Our method first trains the SGM on the entire set of spectra from the hyperspectral image. At test time, each spectrum is passed through a perturbation kernel, and the resulting perturbed spectrum is fed into the trained SGM to obtain the estimated score. The manifold hypothesis of HSIs posits that background spectra reside on one or more low-dimensional manifolds. Conversely, anomalous spectra, owing to their unique spectral signatures, are considered outliers that do not conform to the background manifold. Based on this fundamental discrepancy in their manifold distributions, we leverage a generative SGM to achieve hyperspectral anomaly detection. Experiments on the four hyperspectral datasets demonstrate the effectiveness of the proposed method. The code is available at https://github.com/jiahuisheng/ScoreAD.
Exploring the Intrinsic Probability Distribution for Hyperspectral Anomaly Detection
May 14, 2021


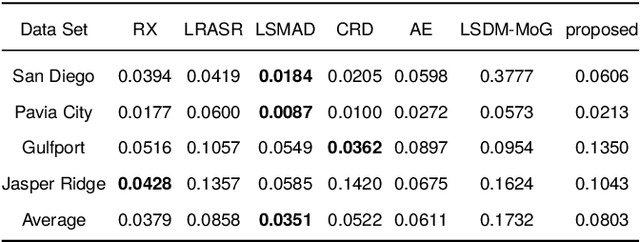
In recent years, neural network-based anomaly detection methods have attracted considerable attention in the hyperspectral remote sensing domain due to the powerful reconstruction ability compared with traditional methods. However, actual probability distribution statistics hidden in the latent space are not discovered by exploiting the reconstruction error because the probability distribution of anomalies is not explicitly modeled. To address the issue, we propose a novel probability distribution representation detector (PDRD) that explores the intrinsic distribution of both the background and the anomalies in original data for hyperspectral anomaly detection in this paper. First, we represent the hyperspectral data with multivariate Gaussian distributions from a probabilistic perspective. Then, we combine the local statistics with the obtained distributions to leverage the spatial information. Finally, the difference between the corresponding distributions of the test pixel and the average expectation of the pixels in the Chebyshev neighborhood is measured by computing the modified Wasserstein distance to acquire the detection map. We conduct the experiments on four real data sets to evaluate the performance of our proposed method. Experimental results demonstrate the accuracy and efficiency of our proposed method compared to the state-of-the-art detection methods.
Multiple Infrared Small Targets Detection based on Hierarchical Maximal Entropy Random Walk
Oct 02, 2020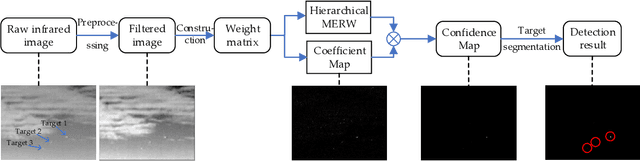

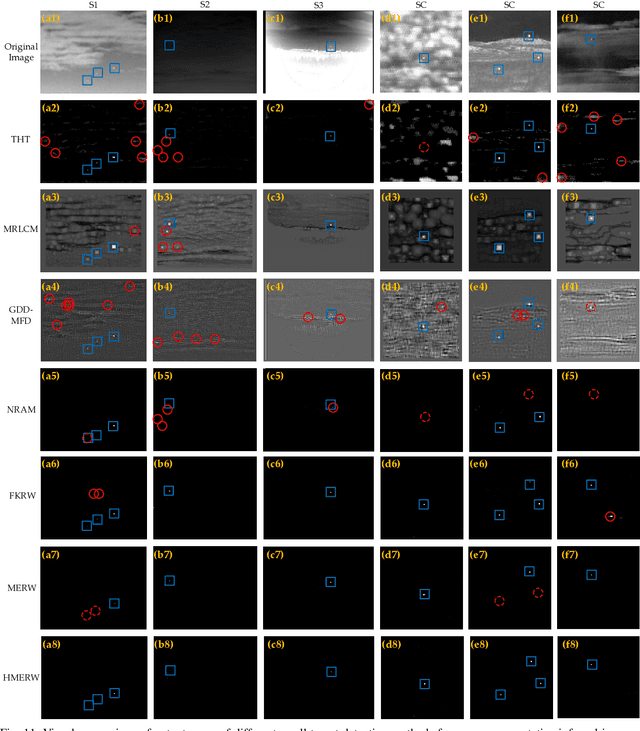
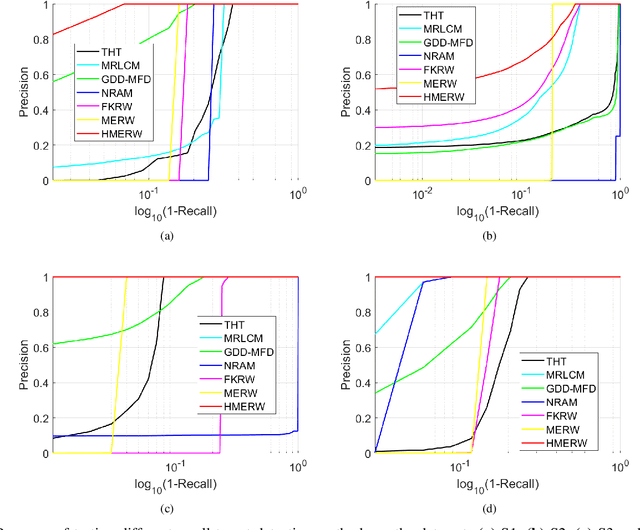
The technique of detecting multiple dim and small targets with low signal-to-clutter ratios (SCR) is very important for infrared search and tracking systems. In this paper, we establish a detection method derived from maximal entropy random walk (MERW) to robustly detect multiple small targets. Initially, we introduce the primal MERW and analyze the feasibility of applying it to small target detection. However, the original weight matrix of the MERW is sensitive to interferences. Therefore, a specific weight matrix is designed for the MERW in principle of enhancing characteristics of small targets and suppressing strong clutters. Moreover, the primal MERW has a critical limitation of strong bias to the most salient small target. To achieve multiple small targets detection, we develop a hierarchical version of the MERW method. Based on the hierarchical MERW (HMERW), we propose a small target detection method as follows. First, filtering technique is used to smooth the infrared image. Second, an output map is obtained by importing the filtered image into the HMERW. Then, a coefficient map is constructed to fuse the stationary dirtribution map of the HMERW. Finally, an adaptive threshold is used to segment multiple small targets from the fusion map. Extensive experiments on practical data sets demonstrate that the proposed method is superior to the state-of-the-art methods in terms of target enhancement, background suppression and multiple small targets detection.
Unsupervised Feature Learning by Autoencoder and Prototypical Contrastive Learning for Hyperspectral Classification
Sep 02, 2020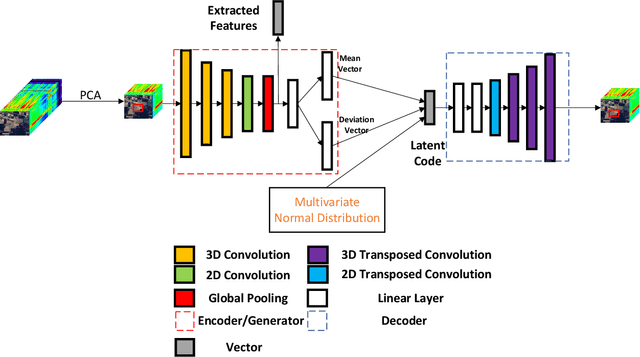
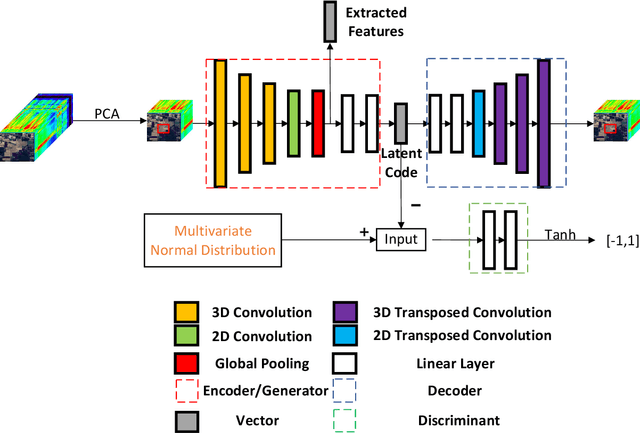
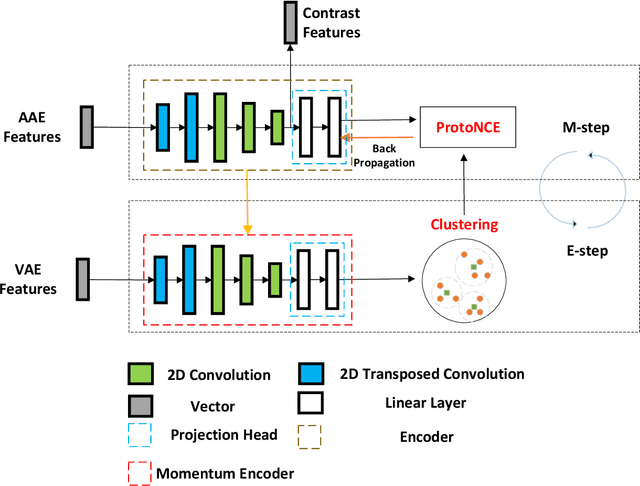
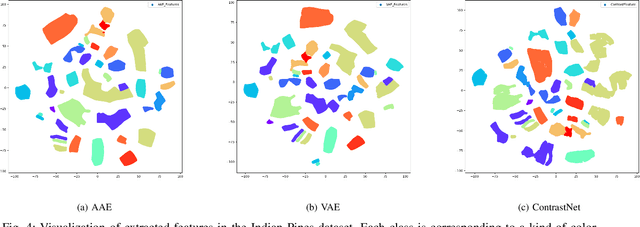
Unsupervised learning methods for feature extraction are becoming more and more popular. We combine the popular contrastive learning method (prototypical contrastive learning) and the classic representation learning method (autoencoder) to design an unsupervised feature learning network for hyperspectral classification. Experiments have proved that our two proposed autoencoder networks have good feature learning capabilities by themselves, and the contrastive learning network we designed can better combine the features of the two to learn more representative features. As a result, our method surpasses other comparison methods in the hyperspectral classification experiments, including some supervised methods. Moreover, our method maintains a fast feature extraction speed than baseline methods. In addition, our method reduces the requirements for huge computing resources, separates feature extraction and contrastive learning, and allows more researchers to conduct research and experiments on unsupervised contrastive learning.