 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch is Enough: Naturalistic Adversarial Patch against Vision-Language Pre-training Models
Oct 07, 2024

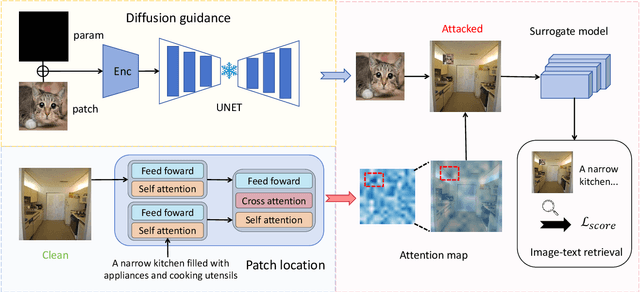
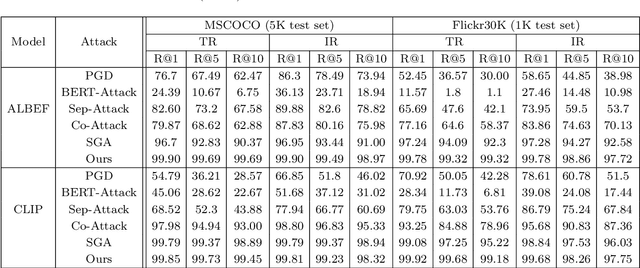
Visual language pre-training (VLP) models have demonstrated significant success across various domains, yet they remain vulnerable to adversarial attacks. Addressing these adversarial vulnerabilities is crucial for enhancing security in multimodal learning. Traditionally, adversarial methods targeting VLP models involve simultaneously perturbing images and text. However, this approach faces notable challenges: first, adversarial perturbations often fail to translate effectively into real-world scenarios; second, direct modifications to the text are conspicuously visible. To overcome these limitations, we propose a novel strategy that exclusively employs image patches for attacks, thus preserving the integrity of the original text. Our method leverages prior knowledge from diffusion models to enhance the authenticity and naturalness of the perturbations. Moreover, to optimize patch placement and improve the efficacy of our attacks, we utilize the cross-attention mechanism, which encapsulates intermodal interactions by generating attention maps to guide strategic patch placements. Comprehensive experiments conducted in a white-box setting for image-to-text scenarios reveal that our proposed method significantly outperforms existing techniques, achieving a 100% attack success rate. Additionally, it demonstrates commendable performance in transfer tasks involving text-to-image configurations.