 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Online Learning Algorithm With Differential Privacy Strategy for Convex Nondecomposable Global Objectives
Jun 16, 2022
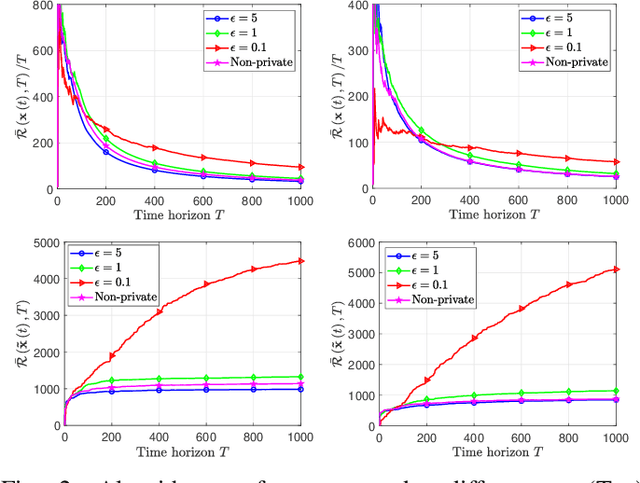
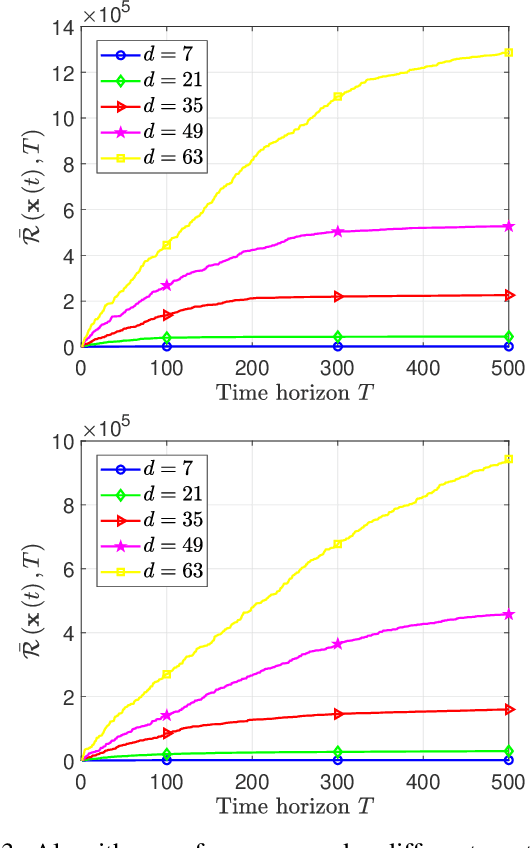
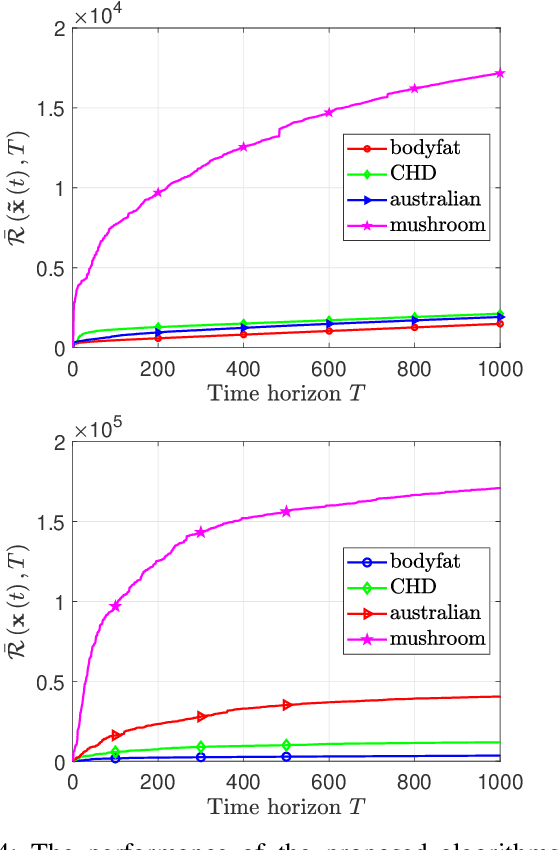
In this paper, we deal with a general distributed constrained online learning problem with privacy over time-varying networks, where a class of nondecomposable objective functions are considered. Under this setting, each node only controls a part of the global decision variable, and the goal of all nodes is to collaboratively minimize the global objective over a time horizon $T$ while guarantees the security of the transmitted information. For such problems, we first design a novel generic algorithm framework, named as DPSDA, of differentially private distributed online learning using the Laplace mechanism and the stochastic variants of dual averaging method. Then, we propose two algorithms, named as DPSDA-C and DPSDA-PS, under this framework. Theoretical results show that both algorithms attain an expected regret upper bound in $\mathcal{O}( \sqrt{T} )$ when the objective function is convex, which matches the best utility achievable by cutting-edge algorithms. Finally, numerical experiment results on both real-world and randomly generated datasets verify the effectiveness of our algorithms.
Local Black-box Adversarial Attacks: A Query Efficient Approach
Jan 04, 2021

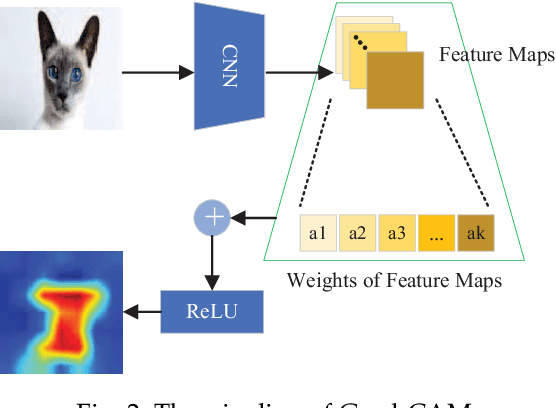

Adversarial attacks have threatened the application of deep neural networks in security-sensitive scenarios. Most existing black-box attacks fool the target model by interacting with it many times and producing global perturbations. However, global perturbations change the smooth and insignificant background, which not only makes the perturbation more easily be perceived but also increases the query overhead. In this paper, we propose a novel framework to perturb the discriminative areas of clean examples only within limited queries in black-box attacks. Our framework is constructed based on two types of transferability. The first one is the transferability of model interpretations. Based on this property, we identify the discriminative areas of a given clean example easily for local perturbations. The second is the transferability of adversarial examples. It helps us to produce a local pre-perturbation for improving query efficiency. After identifying the discriminative areas and pre-perturbing, we generate the final adversarial examples from the pre-perturbed example by querying the targeted model with two kinds of black-box attack techniques, i.e., gradient estimation and random search. We conduct extensive experiments to show that our framework can significantly improve the query efficiency during black-box perturbing with a high attack success rate. Experimental results show that our attacks outperform state-of-the-art black-box attacks under various system settings.