 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust spectral clustering with rank statistics
Aug 19, 2024This paper analyzes the statistical performance of a robust spectral clustering method for latent structure recovery in noisy data matrices. We consider eigenvector-based clustering applied to a matrix of nonparametric rank statistics that is derived entrywise from the raw, original data matrix. This approach is robust in the sense that, unlike traditional spectral clustering procedures, it can provably recover population-level latent block structure even when the observed data matrix includes heavy-tailed entries and has a heterogeneous variance profile. Our main theoretical contributions are threefold and hold under flexible data generating conditions. First, we establish that robust spectral clustering with rank statistics can consistently recover latent block structure, viewed as communities of nodes in a graph, in the sense that unobserved community memberships for all but a vanishing fraction of nodes are correctly recovered with high probability when the data matrix is large. Second, we refine the former result and further establish that, under certain conditions, the community membership of any individual, specified node of interest can be asymptotically exactly recovered with probability tending to one in the large-data limit. Third, we establish asymptotic normality results associated with the truncated eigenstructure of matrices whose entries are rank statistics, made possible by synthesizing contemporary entrywise matrix perturbation analysis with the classical nonparametric theory of so-called simple linear rank statistics. Collectively, these results demonstrate the statistical utility of rank-based data transformations when paired with spectral techniques for dimensionality reduction. Additionally, for a dataset of human connectomes, our approach yields parsimonious dimensionality reduction and improved recovery of ground-truth neuroanatomical cluster structure.
Semi-supervised learning in unbalanced and heterogeneous networks
Jan 07, 2019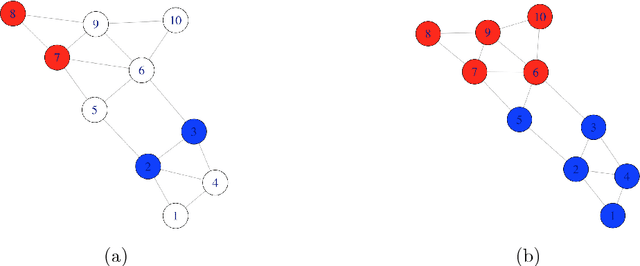

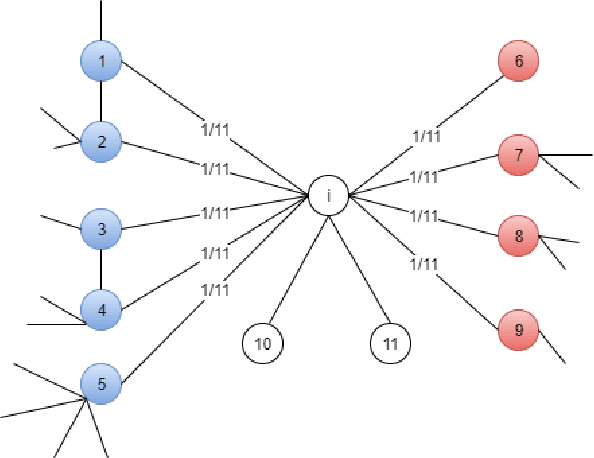

Community detection was a hot topic on network analysis, where the main aim is to perform unsupervised learning or clustering in networks. Recently, semi-supervised learning has received increasing attention among researchers. In this paper, we propose a new algorithm, called weighted inverse Laplacian (WIL), for predicting labels in partially labeled networks. The idea comes from the first hitting time in random walk, and it also has nice explanations both in information propagation and the regularization framework. We propose a partially labeled degree-corrected block model (pDCBM) to describe the generation of partially labeled networks. We show that WIL ensures the misclassification rate is of order $O(\frac{1}{d})$ for the pDCBM with average degree $d=\Omega(\log n),$ and that it can handle situations with greater unbalanced than traditional Laplacian methods. WIL outperforms other state-of-the-art methods in most of our simulations and real datasets, especially in unbalanced networks and heterogeneous networks.