Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-learning Based Optimal False Data Injection Attack on Probabilistic Boolean Control Networks
Nov 29, 2023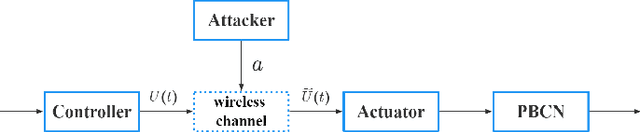
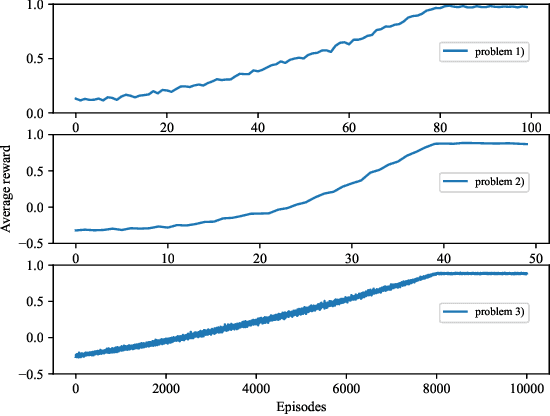
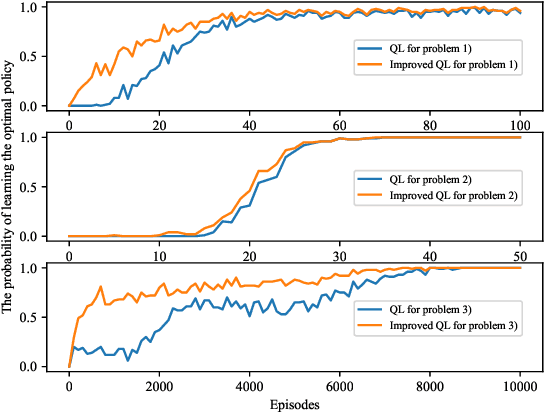
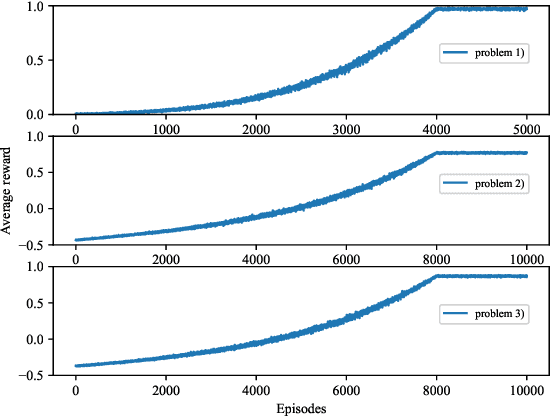
In this paper, we present a reinforcement learning (RL) method for solving optimal false data injection attack problems in probabilistic Boolean control networks (PBCNs) where the attacker lacks knowledge of the system model. Specifically, we employ a Q-learning (QL) algorithm to address this problem. We then propose an improved QL algorithm that not only enhances learning efficiency but also obtains optimal attack strategies for large-scale PBCNs that the standard QL algorithm cannot handle. Finally, we verify the effectiveness of our proposed approach by considering two attacked PBCNs, including a 10-node network and a 28-node network.
Via