 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence analysis of wide shallow neural operators within the framework of Neural Tangent Kernel
Dec 07, 2024Neural operators are aiming at approximating operators mapping between Banach spaces of functions, achieving much success in the field of scientific computing. Compared to certain deep learning-based solvers, such as Physics-Informed Neural Networks (PINNs), Deep Ritz Method (DRM), neural operators can solve a class of Partial Differential Equations (PDEs). Although much work has been done to analyze the approximation and generalization error of neural operators, there is still a lack of analysis on their training error. In this work, we conduct the convergence analysis of gradient descent for the wide shallow neural operators within the framework of Neural Tangent Kernel (NTK). The core idea lies on the fact that over-parameterization and random initialization together ensure that each weight vector remains near its initialization throughout all iterations, yielding the linear convergence of gradient descent. In this work, we demonstrate that under the setting of over-parametrization, gradient descent can find the global minimum regardless of whether it is in continuous time or discrete time.
Convergence Analysis of Natural Gradient Descent for Over-parameterized Physics-Informed Neural Networks
Aug 06, 2024



First-order methods, such as gradient descent (GD) and stochastic gradient descent (SGD), have been proven effective in training neural networks. In the context of over-parameterization, there is a line of work demonstrating that randomly initialized (stochastic) gradient descent converges to a globally optimal solution at a linear convergence rate for the quadratic loss function. However, the learning rate of GD for training two-layer neural networks exhibits poor dependence on the sample size and the Gram matrix, leading to a slow training process. In this paper, we show that for the $L^2$ regression problems, the learning rate can be improved from $\mathcal{O}(\lambda_0/n^2)$ to $\mathcal{O}(1/\|\bm{H}^{\infty}\|_2)$, which implies that GD actually enjoys a faster convergence rate. Furthermore, we generalize the method to GD in training two-layer Physics-Informed Neural Networks (PINNs), showing a similar improvement for the learning rate. Although the improved learning rate has a mild dependence on the Gram matrix, we still need to set it small enough in practice due to the unknown eigenvalues of the Gram matrix. More importantly, the convergence rate is tied to the least eigenvalue of the Gram matrix, which can lead to slow convergence. In this work, we provide the convergence analysis of natural gradient descent (NGD) in training two-layer PINNs, demonstrating that the learning rate can be $\mathcal{O}(1)$, and at this rate, the convergence rate is independent of the Gram matrix.
Convergence of Implicit Gradient Descent for Training Two-Layer Physics-Informed Neural Networks
Jul 03, 2024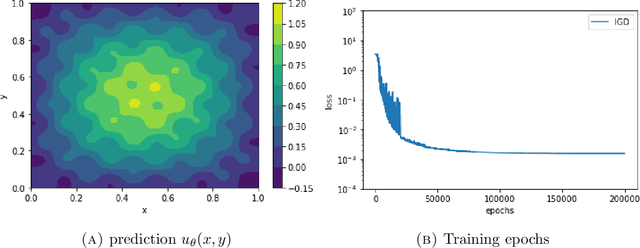
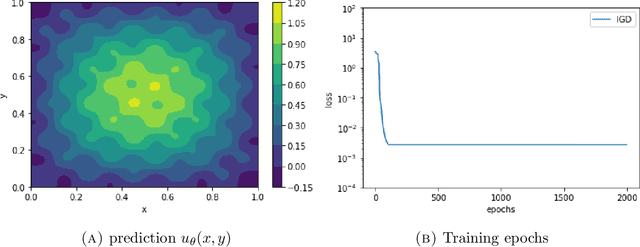
Optimization algorithms is crucial in training physics-informed neural networks (PINNs), unsuitable methods may lead to poor solutions. Compared to the common gradient descent algorithm, implicit gradient descent (IGD) outperforms it in handling some multi-scale problems. In this paper, we provide convergence analysis for the implicit gradient descent for training over-parametrized two-layer PINNs. We first demonstrate the positive definiteness of Gram matrices for general smooth activation functions, like sigmoidal function, softplus function, tanh function and so on. Then the over-parameterization allows us to show that the randomly initialized IGD converges a globally optimal solution at a linear convergence rate. Moreover, due to the different training dynamics, the learning rate of IGD can be chosen independent of the sample size and the least eigenvalue of the Gram matrix.