 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Deterministic Face Mask Removal Based On 3D Priors
Mar 03, 2022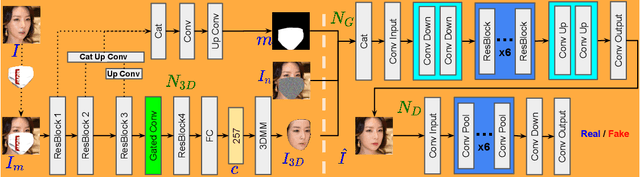


This paper presents a novel image inpainting framework for face mask removal. Although current methods have demonstrated their impressive ability in recovering damaged face images, they suffer from two main problems: the dependence on manually labeled missing regions and the deterministic result corresponding to each input. The proposed approach tackles these problems by integrating a multi-task 3D face reconstruction module with a face inpainting module. Given a masked face image, the former predicts a 3DMM-based reconstructed face together with a binary occlusion map, providing dense geometrical and textural priors that greatly facilitate the inpainting task of the latter. By gradually controlling the 3D shape parameters, our method generates high-quality dynamic inpainting results with different expressions and mouth movements. Qualitative and quantitative experiments verify the effectiveness of the proposed method.
FaceOcc: A Diverse, High-quality Face Occlusion Dataset for Human Face Extraction
Jan 20, 2022



Occlusions often occur in face images in the wild, troubling face-related tasks such as landmark detection, 3D reconstruction, and face recognition. It is beneficial to extract face regions from unconstrained face images accurately. However, current face segmentation datasets suffer from small data volumes, few occlusion types, low resolution, and imprecise annotation, limiting the performance of data-driven-based algorithms. This paper proposes a novel face occlusion dataset with manually labeled face occlusions from the CelebA-HQ and the internet. The occlusion types cover sunglasses, spectacles, hands, masks, scarfs, microphones, etc. To the best of our knowledge, it is by far the largest and most comprehensive face occlusion dataset. Combining it with the attribute mask in CelebAMask-HQ, we trained a straightforward face segmentation model but obtained SOTA performance, convincingly demonstrating the effectiveness of the proposed dataset.
Segmentation-Reconstruction-Guided Facial Image De-occlusion
Dec 15, 2021

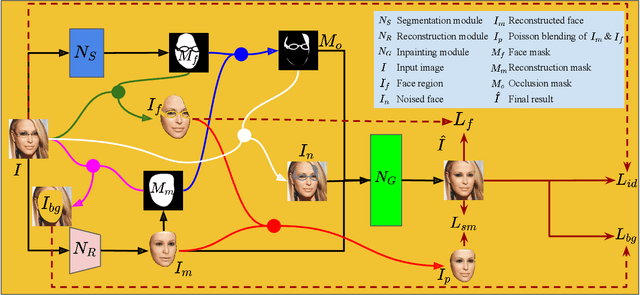
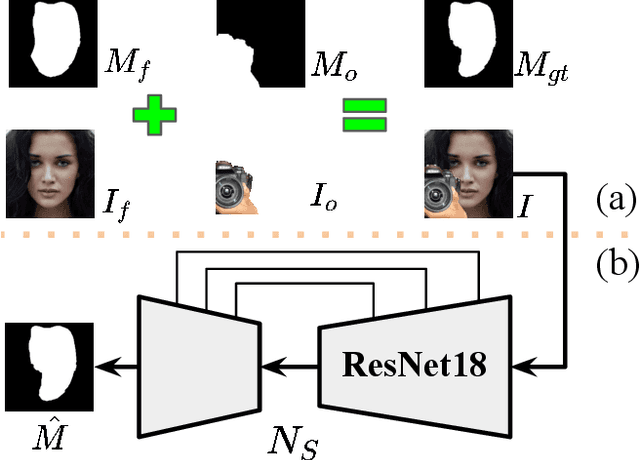
Occlusions are very common in face images in the wild, leading to the degraded performance of face-related tasks. Although much effort has been devoted to removing occlusions from face images, the varying shapes and textures of occlusions still challenge the robustness of current methods. As a result, current methods either rely on manual occlusion masks or only apply to specific occlusions. This paper proposes a novel face de-occlusion model based on face segmentation and 3D face reconstruction, which automatically removes all kinds of face occlusions with even blurred boundaries,e.g., hairs. The proposed model consists of a 3D face reconstruction module, a face segmentation module, and an image generation module. With the face prior and the occlusion mask predicted by the first two, respectively, the image generation module can faithfully recover the missing facial textures. To supervise the training, we further build a large occlusion dataset, with both manually labeled and synthetic occlusions. Qualitative and quantitative results demonstrate the effectiveness and robustness of the proposed method.
Weakly-Supervised Photo-realistic Texture Generation for 3D Face Reconstruction
Jun 14, 2021
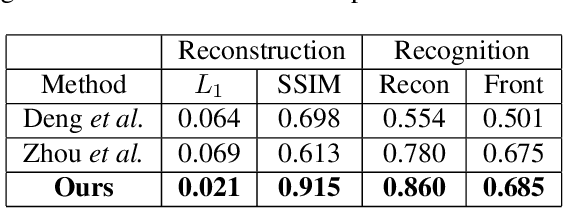
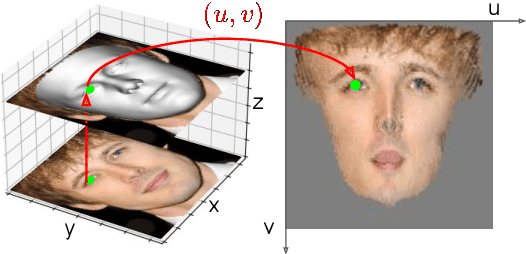
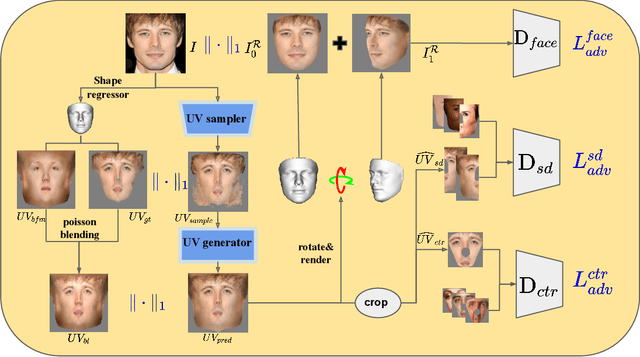
Although much progress has been made recently in 3D face reconstruction, most previous work has been devoted to predicting accurate and fine-grained 3D shapes. In contrast, relatively little work has focused on generating high-fidelity face textures. Compared with the prosperity of photo-realistic 2D face image generation, high-fidelity 3D face texture generation has yet to be studied. In this paper, we proposed a novel UV map generation model that predicts the UV map from a single face image. The model consists of a UV sampler and a UV generator. By selectively sampling the input face image's pixels and adjusting their relative locations, the UV sampler generates an incomplete UV map that could faithfully reconstruct the original face. Missing textures in the incomplete UV map are further full-filled by the UV generator. The training is based on pseudo ground truth blended by the 3DMM texture and the input face texture, thus weakly supervised. To deal with the artifacts in the imperfect pseudo UV map, multiple partial UV map discriminators are leveraged.
Pixel Sampling for Style Preserving Face Pose Editing
Jun 14, 2021


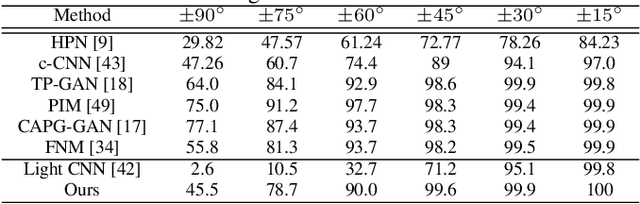
The existing auto-encoder based face pose editing methods primarily focus on modeling the identity preserving ability during pose synthesis, but are less able to preserve the image style properly, which refers to the color, brightness, saturation, etc. In this paper, we take advantage of the well-known frontal/profile optical illusion and present a novel two-stage approach to solve the aforementioned dilemma, where the task of face pose manipulation is cast into face inpainting. By selectively sampling pixels from the input face and slightly adjust their relative locations with the proposed ``Pixel Attention Sampling" module, the face editing result faithfully keeps the identity information as well as the image style unchanged. By leveraging high-dimensional embedding at the inpainting stage, finer details are generated. Further, with the 3D facial landmarks as guidance, our method is able to manipulate face pose in three degrees of freedom, i.e., yaw, pitch, and roll, resulting in more flexible face pose editing than merely controlling the yaw angle as usually achieved by the current state-of-the-art. Both the qualitative and quantitative evaluations validate the superiority of the proposed approach.