 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Aware Learnable Graph Pooling Tokens as Prompt for Large Language Models
Jan 29, 2025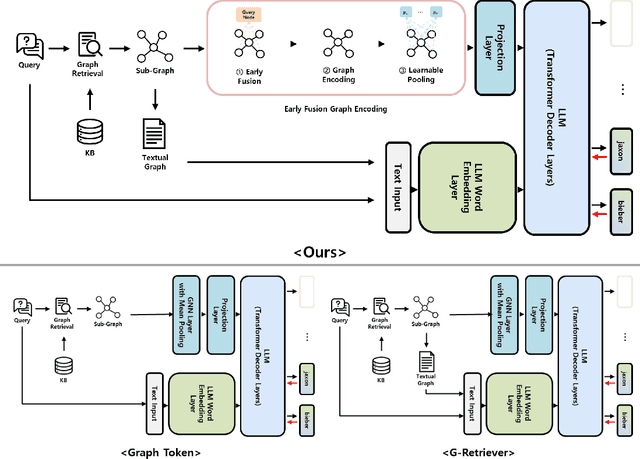


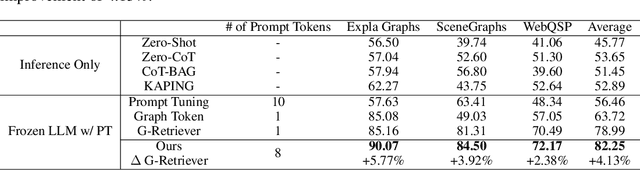
Graph-structured data plays a vital role in numerous domains, such as social networks, citation networks, commonsense reasoning graphs and knowledge graphs. While graph neural networks have been employed for graph processing, recent advancements have explored integrating large language models for graph-based tasks. In this paper, we propose a novel approach named Learnable Graph Pooling Token (LGPT), which addresses the limitations of the scalability issues in node-level projection and information loss in graph-level projection. LGPT enables flexible and efficient graph representation by introducing learnable parameters that act as tokens in large language models, balancing fine-grained and global graph information. Additionally, we investigate an Early Query Fusion technique, which fuses query context before constructing the graph representation, leading to more effective graph embeddings. Our method achieves a 4.13\% performance improvement on the GraphQA benchmark without training the large language model, demonstrating significant gains in handling complex textual-attributed graph data.
Marvelous Agglutinative Language Effect on Cross Lingual Transfer Learning
Apr 08, 2022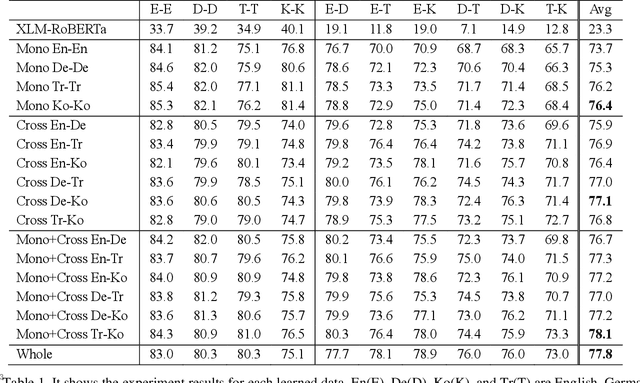
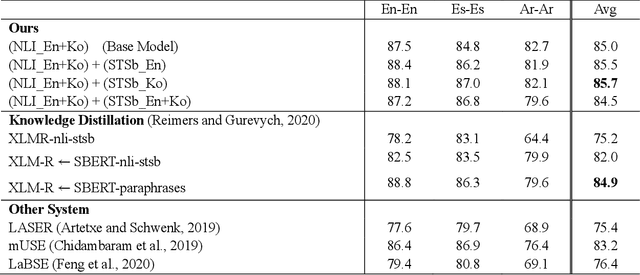
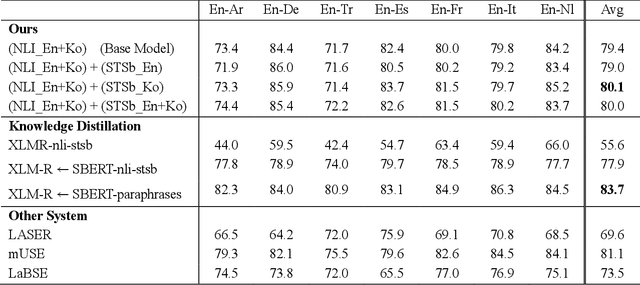
As for multilingual language models, it is important to select languages for training because of the curse of multilinguality. (Conneau et al., 2020). It is known that using languages with similar language structures is effective for cross lingual transfer learning (Pires et al., 2019). However, we demonstrate that using agglutinative languages such as Korean is more effective in cross lingual transfer learning. This is a great discovery that will change the training strategy of cross lingual transfer learning.