 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMATANet: A Multi-context Attention and Taxonomy-Aware Network for Fine-Grained Underwater Recognition of Marine Species
Jan 07, 2026Fine-grained classification of marine animals supports ecology, biodiversity and habitat conservation, and evidence-based policy-making. However, existing methods often overlook contextual interactions from the surrounding environment and insufficiently incorporate the hierarchical structure of marine biological taxonomy. To address these challenges, we propose MATANet (Multi-context Attention and Taxonomy-Aware Network), a novel model designed for fine-grained marine species classification. MATANet mimics expert strategies by using taxonomy and environmental context to interpret ambiguous features of underwater animals. It consists of two key components: a Multi-Context Environmental Attention Module (MCEAM), which learns relationships between regions of interest (ROIs) and their surrounding environments, and a Hierarchical Separation-Induced Learning Module (HSLM), which encodes taxonomic hierarchy into the feature space. MATANet combines instance and environmental features with taxonomic structure to enhance fine-grained classification. Experiments on the FathomNet2025, FAIR1M, and LifeCLEF2015-Fish datasets demonstrate state-of-the-art performance. The source code is available at: https://github.com/dhlee-work/fathomnet-cvpr2025-ssl
Real-Time Person Image Synthesis Using a Flow Matching Model
May 06, 2025Pose-Guided Person Image Synthesis (PGPIS) generates realistic person images conditioned on a target pose and a source image. This task plays a key role in various real-world applications, such as sign language video generation, AR/VR, gaming, and live streaming. In these scenarios, real-time PGPIS is critical for providing immediate visual feedback and maintaining user immersion.However, achieving real-time performance remains a significant challenge due to the complexity of synthesizing high-fidelity images from diverse and dynamic human poses. Recent diffusion-based methods have shown impressive image quality in PGPIS, but their slow sampling speeds hinder deployment in time-sensitive applications. This latency is particularly problematic in tasks like generating sign language videos during live broadcasts, where rapid image updates are required. Therefore, developing a fast and reliable PGPIS model is a crucial step toward enabling real-time interactive systems. To address this challenge, we propose a generative model based on flow matching (FM). Our approach enables faster, more stable, and more efficient training and sampling. Furthermore, the proposed model supports conditional generation and can operate in latent space, making it especially suitable for real-time PGPIS applications where both speed and quality are critical. We evaluate our proposed method, Real-Time Person Image Synthesis Using a Flow Matching Model (RPFM), on the widely used DeepFashion dataset for PGPIS tasks. Our results show that RPFM achieves near-real-time sampling speeds while maintaining performance comparable to the state-of-the-art models. Our methodology trades off a slight, acceptable decrease in generated-image accuracy for over a twofold increase in generation speed, thereby ensuring real-time performance.
Query-Aware Learnable Graph Pooling Tokens as Prompt for Large Language Models
Jan 29, 2025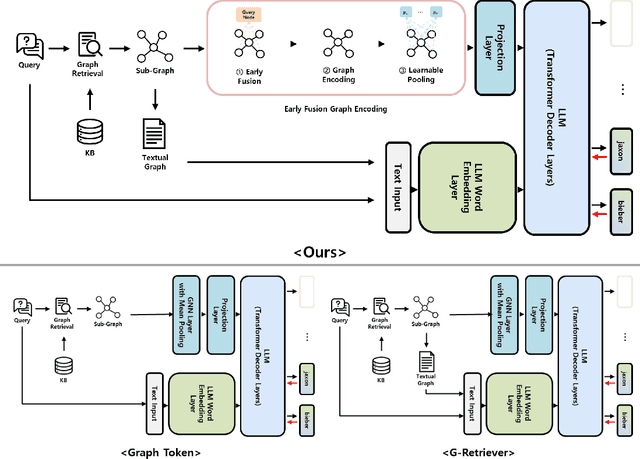


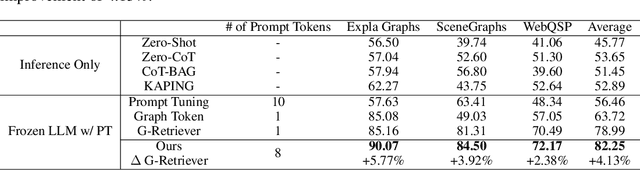
Graph-structured data plays a vital role in numerous domains, such as social networks, citation networks, commonsense reasoning graphs and knowledge graphs. While graph neural networks have been employed for graph processing, recent advancements have explored integrating large language models for graph-based tasks. In this paper, we propose a novel approach named Learnable Graph Pooling Token (LGPT), which addresses the limitations of the scalability issues in node-level projection and information loss in graph-level projection. LGPT enables flexible and efficient graph representation by introducing learnable parameters that act as tokens in large language models, balancing fine-grained and global graph information. Additionally, we investigate an Early Query Fusion technique, which fuses query context before constructing the graph representation, leading to more effective graph embeddings. Our method achieves a 4.13\% performance improvement on the GraphQA benchmark without training the large language model, demonstrating significant gains in handling complex textual-attributed graph data.
Fusion Embedding for Pose-Guided Person Image Synthesis with Diffusion Model
Dec 10, 2024Pose-Guided Person Image Synthesis (PGPIS) aims to synthesize high-quality person images corresponding to target poses while preserving the appearance of the source image. Recently, PGPIS methods that use diffusion models have achieved competitive performance. Most approaches involve extracting representations of the target pose and source image and learning their relationships in the generative model's training process. This approach makes it difficult to learn the semantic relationships between the input and target images and complicates the model structure needed to enhance generation results. To address these issues, we propose Fusion embedding for PGPIS using a Diffusion Model (FPDM). Inspired by the successful application of pre-trained CLIP models in text-to-image diffusion models, our method consists of two stages. The first stage involves training the fusion embedding of the source image and target pose to align with the target image's embedding. In the second stage, the generative model uses this fusion embedding as a condition to generate the target image. We applied the proposed method to the benchmark datasets DeepFashion and RWTH-PHOENIX-Weather 2014T, and conducted both quantitative and qualitative evaluations, demonstrating state-of-the-art (SOTA) performance. An ablation study of the model structure showed that even a model using only the second stage achieved performance close to the other PGPIS SOTA models. The code is available at https://github.com/dhlee-work/FPDM.
Learning Similarity among Users for Personalized Session-Based Recommendation from hierarchical structure of User-Session-Item
Jun 05, 2023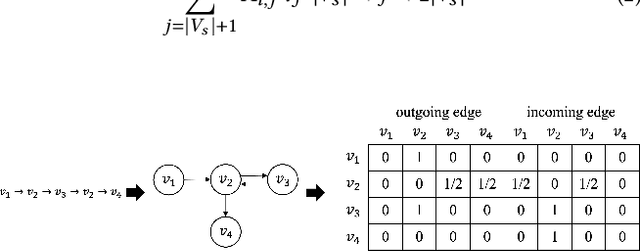
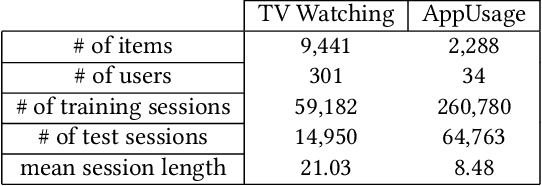
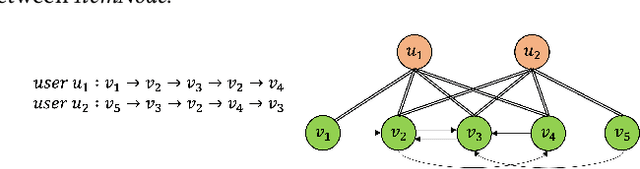

The task of the session-based recommendation is to predict the next interaction of the user based on the anonymized user's behavior pattern. And personalized version of this system is a promising research field due to its availability to deal with user information. However, there's a problem that the user's preferences and historical sessions were not considered in the typical session-based recommendation since it concentrates only on user-item interaction. In addition, the existing personalized session-based recommendation model has a limited capability in that it only considers the preference of the current user without considering those of similar users. It means there can be the loss of information included within the hierarchical data structure of the user-session-item. To tackle with this problem, we propose USP-SBR(abbr. of User Similarity Powered - Session Based Recommender). To model global historical sessions of users, we propose UserGraph that has two types of nodes - ItemNode and UserNode. We then connect the nodes with three types of edges. The first type of edges connects ItemNode as chronological order, and the second connects ItemNode to UserNode, and the last connects UserNode to ItemNode. With these user embeddings, we propose additional contrastive loss, that makes users with similar intention be close to each other in the vector space. we apply graph neural network on these UserGraph and update nodes. Experimental results on two real-world datasets demonstrate that our method outperforms some state-of-the-art approaches.
Marvelous Agglutinative Language Effect on Cross Lingual Transfer Learning
Apr 08, 2022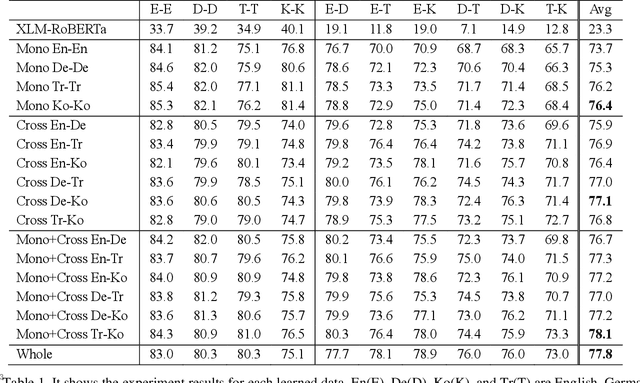
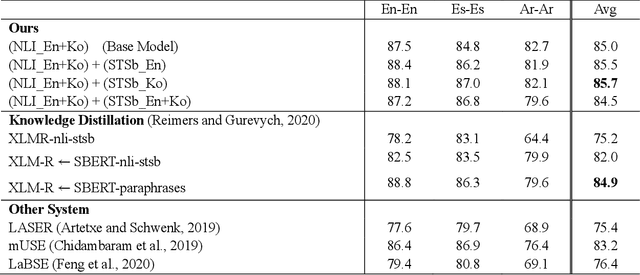
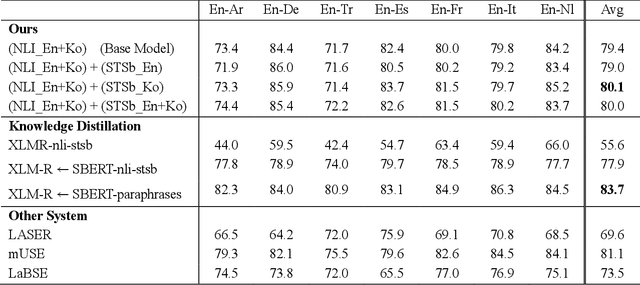
As for multilingual language models, it is important to select languages for training because of the curse of multilinguality. (Conneau et al., 2020). It is known that using languages with similar language structures is effective for cross lingual transfer learning (Pires et al., 2019). However, we demonstrate that using agglutinative languages such as Korean is more effective in cross lingual transfer learning. This is a great discovery that will change the training strategy of cross lingual transfer learning.