 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARVQ: Corrective Adaptor with Group Residual Vector Quantization for LLM Embedding Compression
Oct 14, 2025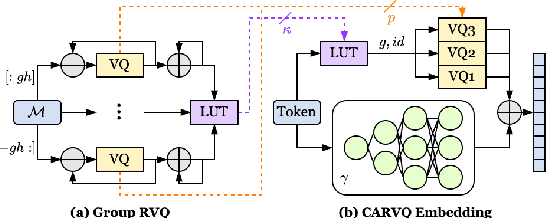
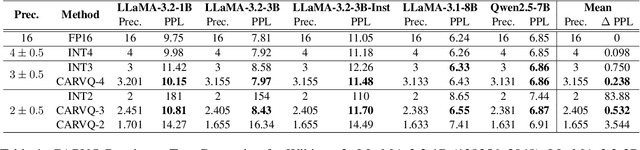
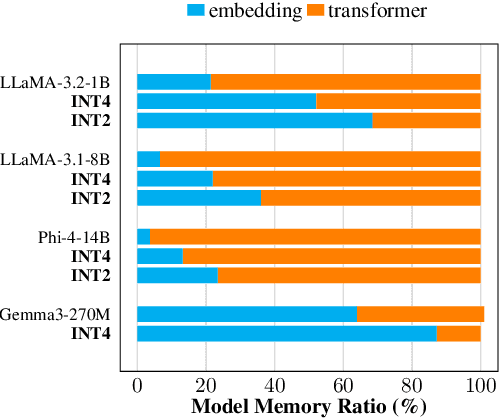
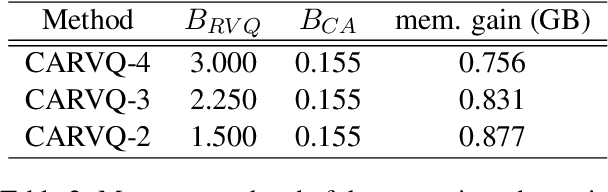
Large Language Models (LLMs) typically rely on a large number of parameters for token embedding, leading to substantial storage requirements and memory footprints. In particular, LLMs deployed on edge devices are memory-bound, and reducing the memory footprint by compressing the embedding layer not only frees up the memory bandwidth but also speeds up inference. To address this, we introduce CARVQ, a post-training novel Corrective Adaptor combined with group Residual Vector Quantization. CARVQ relies on the composition of both linear and non-linear maps and mimics the original model embedding to compress to approximately 1.6 bits without requiring specialized hardware to support lower-bit storage. We test our method on pre-trained LLMs such as LLaMA-3.2-1B, LLaMA-3.2-3B, LLaMA-3.2-3B-Instruct, LLaMA-3.1-8B, Qwen2.5-7B, Qwen2.5-Math-7B and Phi-4, evaluating on common generative, discriminative, math and reasoning tasks. We show that in most cases, CARVQ can achieve lower average bitwidth-per-parameter while maintaining reasonable perplexity and accuracy compared to scalar quantization. Our contributions include a novel compression technique that is compatible with state-of-the-art transformer quantization methods and can be seamlessly integrated into any hardware supporting 4-bit memory to reduce the model's memory footprint in memory-constrained devices. This work demonstrates a crucial step toward the efficient deployment of LLMs on edge devices.
OneNet: A Channel-Wise 1D Convolutional U-Net
Nov 14, 2024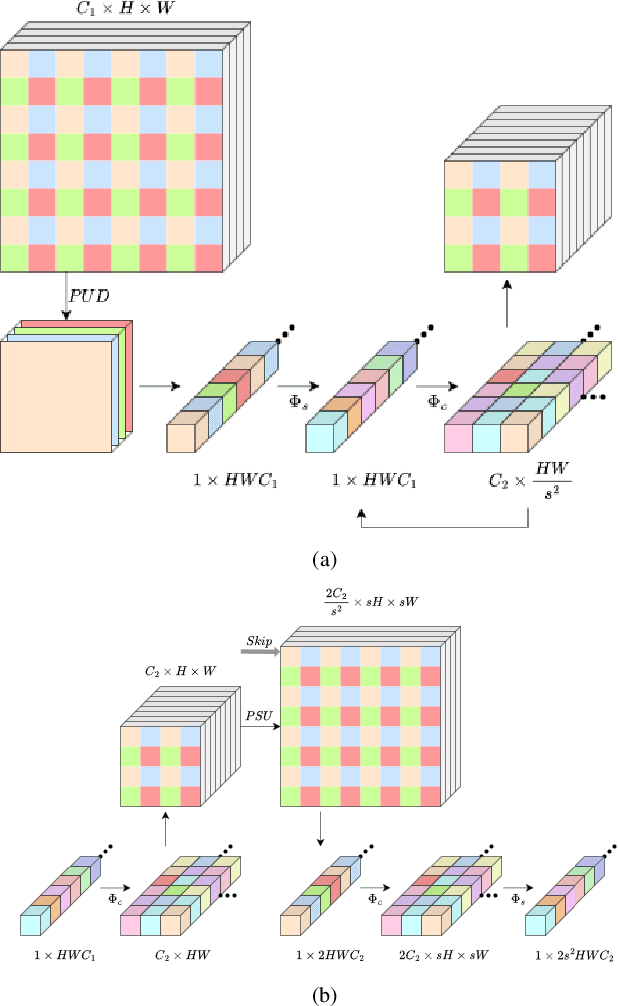
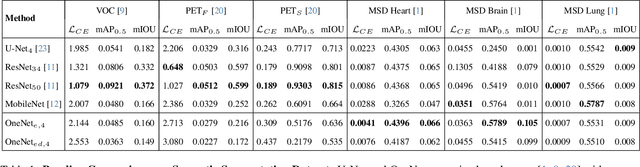
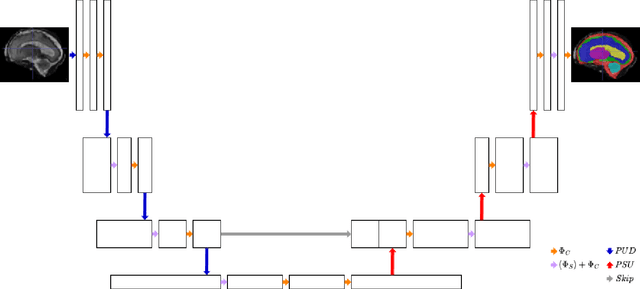
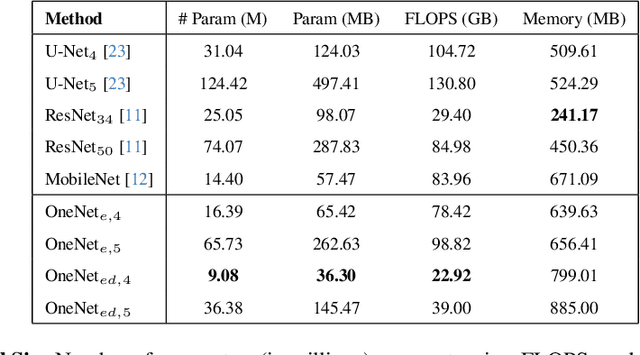
Many state-of-the-art computer vision architectures leverage U-Net for its adaptability and efficient feature extraction. However, the multi-resolution convolutional design often leads to significant computational demands, limiting deployment on edge devices. We present a streamlined alternative: a 1D convolutional encoder that retains accuracy while enhancing its suitability for edge applications. Our novel encoder architecture achieves semantic segmentation through channel-wise 1D convolutions combined with pixel-unshuffle operations. By incorporating PixelShuffle, known for improving accuracy in super-resolution tasks while reducing computational load, OneNet captures spatial relationships without requiring 2D convolutions, reducing parameters by up to 47%. Additionally, we explore a fully 1D encoder-decoder that achieves a 71% reduction in size, albeit with some accuracy loss. We benchmark our approach against U-Net variants across diverse mask-generation tasks, demonstrating that it preserves accuracy effectively. Although focused on image segmentation, this architecture is adaptable to other convolutional applications. Code for the project is available at https://github.com/shbyun080/OneNet .
MultiDepth: Multi-Sample Priors for Refining Monocular Metric Depth Estimations in Indoor Scenes
Nov 01, 2024Monocular metric depth estimation (MMDE) is a crucial task to solve for indoor scene reconstruction on edge devices. Despite this importance, existing models are sensitive to factors such as boundary frequency of objects in the scene and scene complexity, failing to fully capture many indoor scenes. In this work, we propose to close this gap through the task of monocular metric depth refinement (MMDR) by leveraging state-of-the-art MMDE models. MultiDepth proposes a solution by taking samples of the image along with the initial depth map prediction made by a pre-trained MMDE model. Compared to existing iterative depth refinement techniques, MultiDepth does not employ normal map prediction as part of its architecture, effectively lowering the model size and computation overhead while outputting impactful changes from refining iterations. MultiDepth implements a lightweight encoder-decoder architecture for the refinement network, processing multiple samples from the given image, including segmentation masking. We evaluate MultiDepth on four datasets and compare them to state-of-the-art methods to demonstrate its effective refinement with minimal overhead, displaying accuracy improvement upward of 45%.