 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneNet: A Channel-Wise 1D Convolutional U-Net
Paper and Code
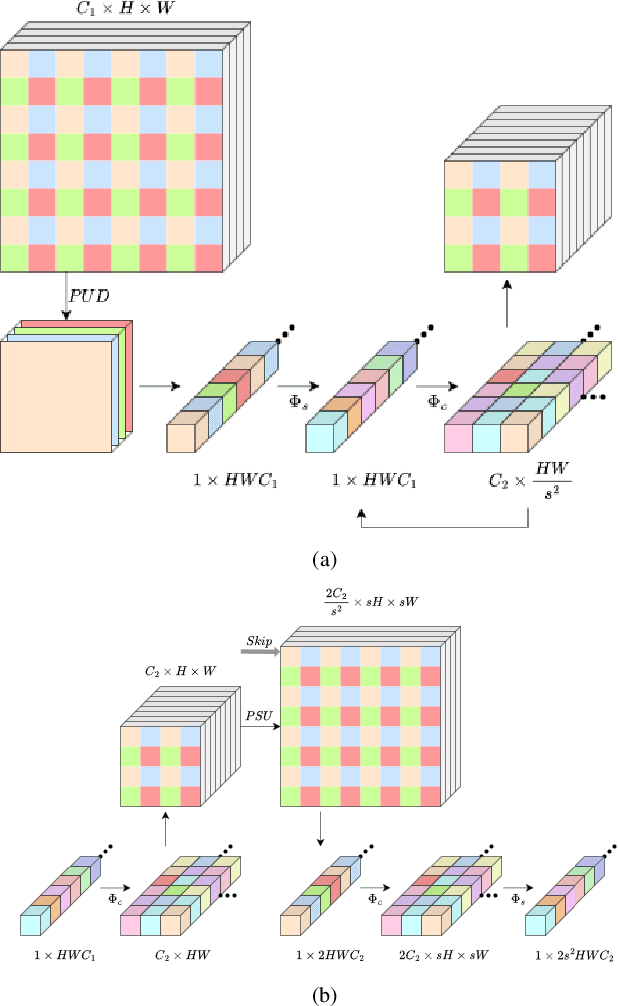
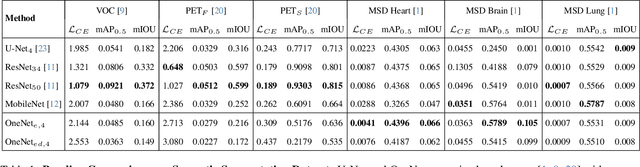
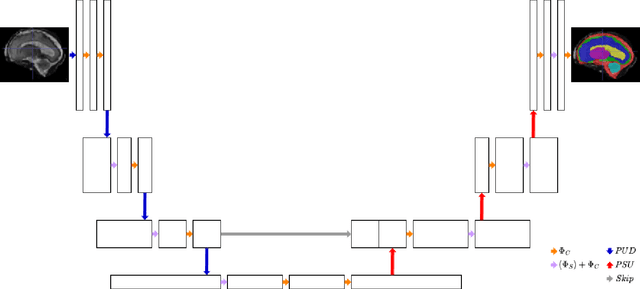
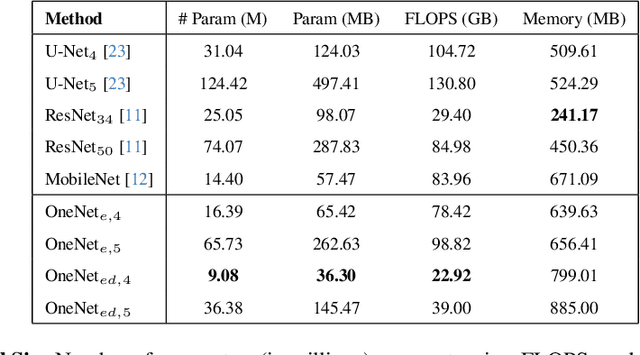
Many state-of-the-art computer vision architectures leverage U-Net for its adaptability and efficient feature extraction. However, the multi-resolution convolutional design often leads to significant computational demands, limiting deployment on edge devices. We present a streamlined alternative: a 1D convolutional encoder that retains accuracy while enhancing its suitability for edge applications. Our novel encoder architecture achieves semantic segmentation through channel-wise 1D convolutions combined with pixel-unshuffle operations. By incorporating PixelShuffle, known for improving accuracy in super-resolution tasks while reducing computational load, OneNet captures spatial relationships without requiring 2D convolutions, reducing parameters by up to 47%. Additionally, we explore a fully 1D encoder-decoder that achieves a 71% reduction in size, albeit with some accuracy loss. We benchmark our approach against U-Net variants across diverse mask-generation tasks, demonstrating that it preserves accuracy effectively. Although focused on image segmentation, this architecture is adaptable to other convolutional applications. Code for the project is available at https://github.com/shbyun080/OneNet .