 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Autoregressive Flows for Zero Degree Calorimeter fast simulation
Dec 23, 2025


Physics-based machine learning blends traditional science with modern data-driven techniques. Rather than relying exclusively on empirical data or predefined equations, this methodology embeds domain knowledge directly into the learning process, resulting in models that are both more accurate and robust. We leverage this paradigm to accelerate simulations of the Zero Degree Calorimeter (ZDC) of the ALICE experiment at CERN. Our method introduces a novel loss function and an output variability-based scaling mechanism, which enhance the model's capability to accurately represent the spatial distribution and morphology of particle showers in detector outputs while mitigating the influence of rare artefacts on the training. Leveraging Normalizing Flows (NFs) in a teacher-student generative framework, we demonstrate that our approach not only outperforms classic data-driven model assimilation but also yields models that are 421 times faster than existing NF implementations in ZDC simulation literature.
Quasi-optimal $hp$-finite element refinements towards singularities via deep neural network prediction
Sep 13, 2022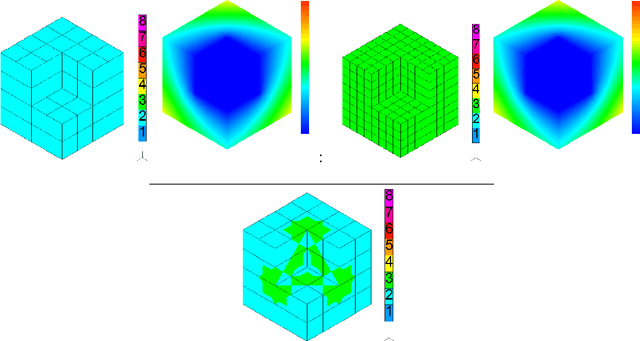

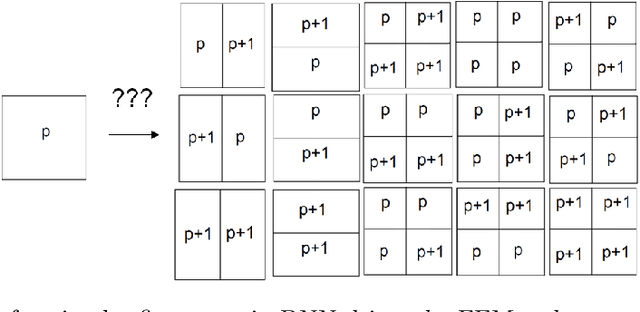
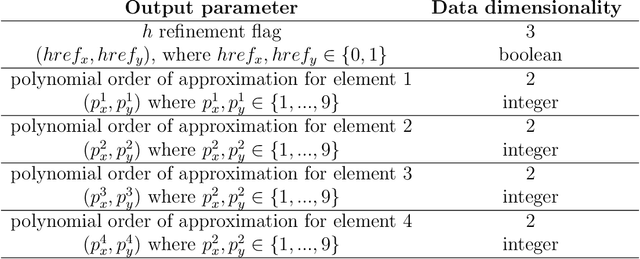
We show how to construct the deep neural network (DNN) expert to predict quasi-optimal $hp$-refinements for a given computational problem. The main idea is to train the DNN expert during executing the self-adaptive $hp$-finite element method ($hp$-FEM) algorithm and use it later to predict further $hp$ refinements. For the training, we use a two-grid paradigm self-adaptive $hp$-FEM algorithm. It employs the fine mesh to provide the optimal $hp$ refinements for coarse mesh elements. We aim to construct the DNN expert to identify quasi-optimal $hp$ refinements of the coarse mesh elements. During the training phase, we use the direct solver to obtain the solution for the fine mesh to guide the optimal refinements over the coarse mesh element. After training, we turn off the self-adaptive $hp$-FEM algorithm and continue with quasi-optimal refinements as proposed by the DNN expert trained. We test our method on three-dimensional Fichera and two-dimensional L-shaped domain problems. We verify the convergence of the numerical accuracy with respect to the mesh size. We show that the exponential convergence delivered by the self-adaptive $hp$-FEM can be preserved if we continue refinements with a properly trained DNN expert. Thus, in this paper, we show that from the self-adaptive $hp$-FEM it is possible to train the DNN expert the location of the singularities, and continue with the selection of the quasi-optimal $hp$ refinements, preserving the exponential convergence of the method.
SuperNet -- An efficient method of neural networks ensembling
Mar 29, 2020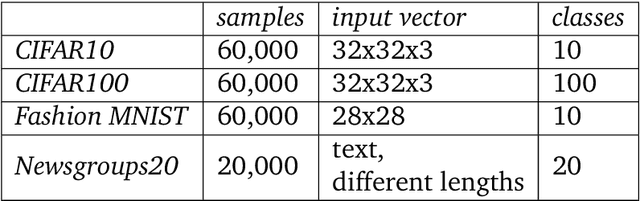
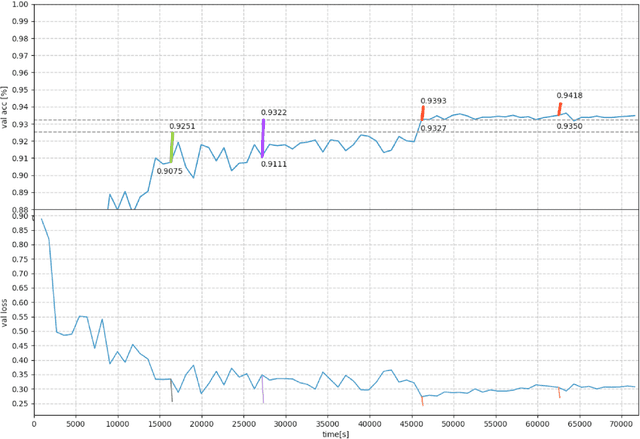
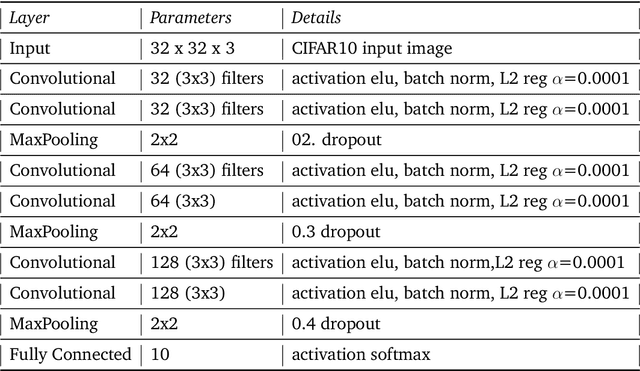
The main flaw of neural network ensembling is that it is exceptionally demanding computationally, especially, if the individual sub-models are large neural networks, which must be trained separately. Having in mind that modern DNNs can be very accurate, they are already the huge ensembles of simple classifiers, and that one can construct more thrifty compressed neural net of a similar performance for any ensemble, the idea of designing the expensive SuperNets can be questionable. The widespread belief that ensembling increases the prediction time, makes it not attractive and can be the reason that the main stream of ML research is directed towards developing better loss functions and learning strategies for more advanced and efficient neural networks. On the other hand, all these factors make the architectures more complex what may lead to overfitting and high computational complexity, that is, to the same flaws for which the highly parametrized SuperNets ensembles are blamed. The goal of the master thesis is to speed up the execution time required for ensemble generation. Instead of training K inaccurate sub-models, each of them can represent various phases of training (representing various local minima of the loss function) of a single DNN [Huang et al., 2017; Gripov et al., 2018]. Thus, the computational performance of the SuperNet can be comparable to the maximum CPU time spent on training its single sub-model, plus usually much shorter CPU time required for training the SuperNet coupling factors.
2-D Embedding of Large and High-dimensional Data with Minimal Memory and Computational Time Requirements
Feb 04, 2019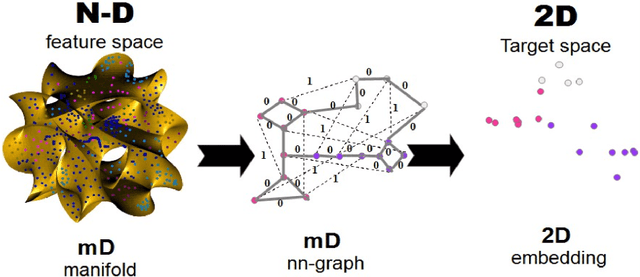

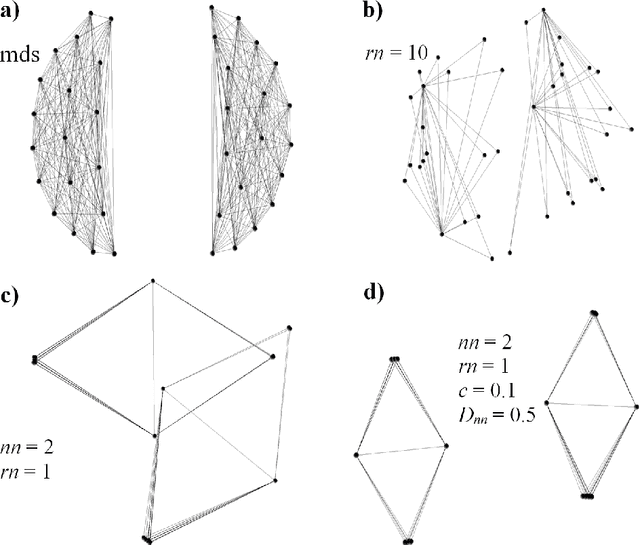

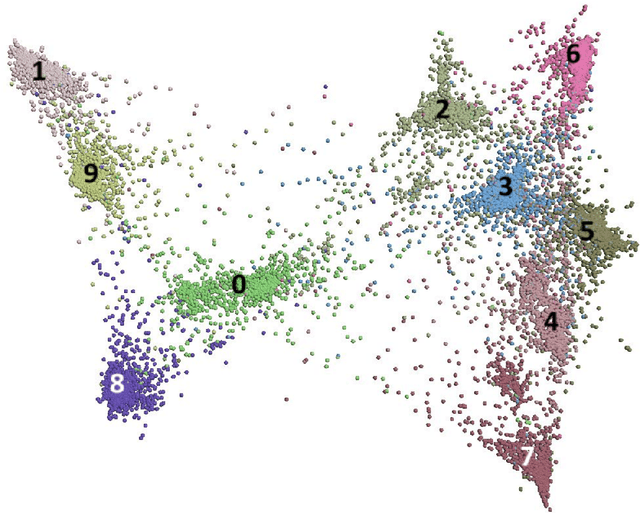
In the advent of big data era, interactive visualization of large data sets consisting of M*10^5+ high-dimensional feature vectors of length N (N ~ 10^3+), is an indispensable tool for data exploratory analysis. The state-of-the-art data embedding (DE) methods of N-D data into 2-D (3-D) visually perceptible space (e.g., based on t-SNE concept) are too demanding computationally to be efficiently employed for interactive data analytics of large and high-dimensional datasets. Herein we present a simple method, ivhd (interactive visualization of high-dimensional data tool), which radically outperforms the modern data-embedding algorithms in both computational and memory loads, while retaining high quality of N-D data embedding in 2-D (3-D). We show that DE problem is equivalent to the nearest neighbor nn-graph visualization, where only indices of a few nearest neighbors of each data sample has to be known, and binary distance between data samples -- 0 to the nearest and 1 to the other samples -- is defined. These improvements reduce the time-complexity and memory load from O(M log M) to O(M), and ensure minimal O(M) proportionality coefficient as well. We demonstrate high efficiency, quality and robustness of ivhd on popular benchmark datasets such as MNIST, 20NG, NORB and RCV1.