 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic stabilization of finite-element simulations using neural networks and hierarchical matrices
Dec 24, 2022Petrov-Galerkin formulations with optimal test functions allow for the stabilization of finite element simulations. In particular, given a discrete trial space, the optimal test space induces a numerical scheme delivering the best approximation in terms of a problem-dependent energy norm. This ideal approach has two shortcomings: first, we need to explicitly know the set of optimal test functions; and second, the optimal test functions may have large supports inducing expensive dense linear systems. Nevertheless, parametric families of PDEs are an example where it is worth investing some (offline) computational effort to obtain stabilized linear systems that can be solved efficiently, for a given set of parameters, in an online stage. Therefore, as a remedy for the first shortcoming, we explicitly compute (offline) a function mapping any PDE-parameter, to the matrix of coefficients of optimal test functions (in a basis expansion) associated with that PDE-parameter. Next, as a remedy for the second shortcoming, we use the low-rank approximation to hierarchically compress the (non-square) matrix of coefficients of optimal test functions. In order to accelerate this process, we train a neural network to learn a critical bottleneck of the compression algorithm (for a given set of PDE-parameters). When solving online the resulting (compressed) Petrov-Galerkin formulation, we employ a GMRES iterative solver with inexpensive matrix-vector multiplications thanks to the low-rank features of the compressed matrix. We perform experiments showing that the full online procedure as fast as the original (unstable) Galerkin approach. In other words, we get the stabilization with hierarchical matrices and neural networks practically for free. We illustrate our findings by means of 2D Eriksson-Johnson and Hemholtz model problems.
Quasi-optimal $hp$-finite element refinements towards singularities via deep neural network prediction
Sep 13, 2022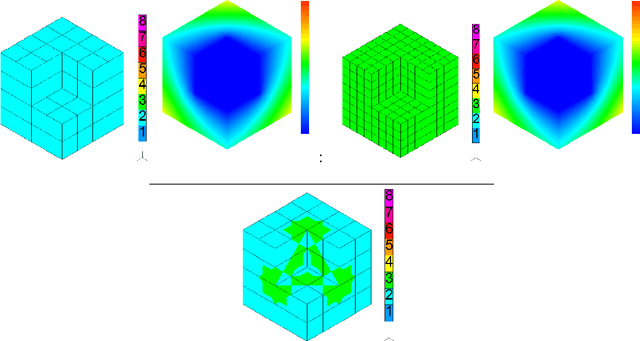

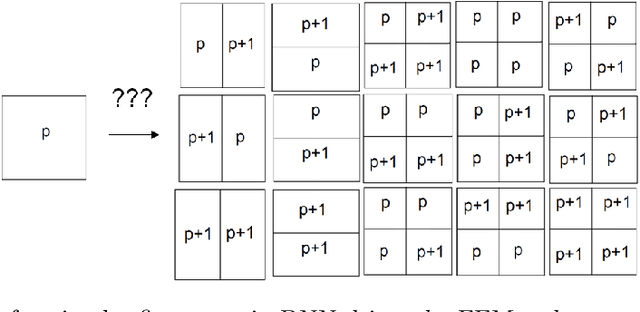
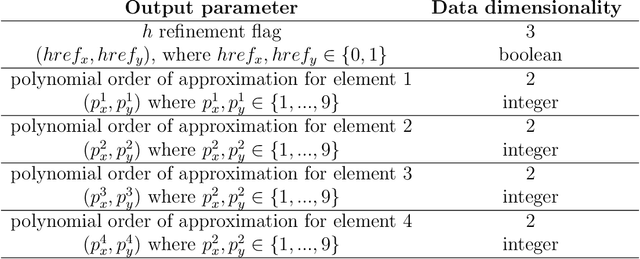
We show how to construct the deep neural network (DNN) expert to predict quasi-optimal $hp$-refinements for a given computational problem. The main idea is to train the DNN expert during executing the self-adaptive $hp$-finite element method ($hp$-FEM) algorithm and use it later to predict further $hp$ refinements. For the training, we use a two-grid paradigm self-adaptive $hp$-FEM algorithm. It employs the fine mesh to provide the optimal $hp$ refinements for coarse mesh elements. We aim to construct the DNN expert to identify quasi-optimal $hp$ refinements of the coarse mesh elements. During the training phase, we use the direct solver to obtain the solution for the fine mesh to guide the optimal refinements over the coarse mesh element. After training, we turn off the self-adaptive $hp$-FEM algorithm and continue with quasi-optimal refinements as proposed by the DNN expert trained. We test our method on three-dimensional Fichera and two-dimensional L-shaped domain problems. We verify the convergence of the numerical accuracy with respect to the mesh size. We show that the exponential convergence delivered by the self-adaptive $hp$-FEM can be preserved if we continue refinements with a properly trained DNN expert. Thus, in this paper, we show that from the self-adaptive $hp$-FEM it is possible to train the DNN expert the location of the singularities, and continue with the selection of the quasi-optimal $hp$ refinements, preserving the exponential convergence of the method.