 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2-D Embedding of Large and High-dimensional Data with Minimal Memory and Computational Time Requirements
Feb 04, 2019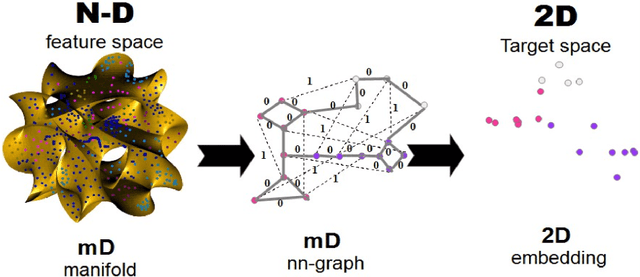


In the advent of big data era, interactive visualization of large data sets consisting of M*10^5+ high-dimensional feature vectors of length N (N ~ 10^3+), is an indispensable tool for data exploratory analysis. The state-of-the-art data embedding (DE) methods of N-D data into 2-D (3-D) visually perceptible space (e.g., based on t-SNE concept) are too demanding computationally to be efficiently employed for interactive data analytics of large and high-dimensional datasets. Herein we present a simple method, ivhd (interactive visualization of high-dimensional data tool), which radically outperforms the modern data-embedding algorithms in both computational and memory loads, while retaining high quality of N-D data embedding in 2-D (3-D). We show that DE problem is equivalent to the nearest neighbor nn-graph visualization, where only indices of a few nearest neighbors of each data sample has to be known, and binary distance between data samples -- 0 to the nearest and 1 to the other samples -- is defined. These improvements reduce the time-complexity and memory load from O(M log M) to O(M), and ensure minimal O(M) proportionality coefficient as well. We demonstrate high efficiency, quality and robustness of ivhd on popular benchmark datasets such as MNIST, 20NG, NORB and RCV1.