 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Approximate Cross-Validation for High-Dimensional GLMs
May 31, 2019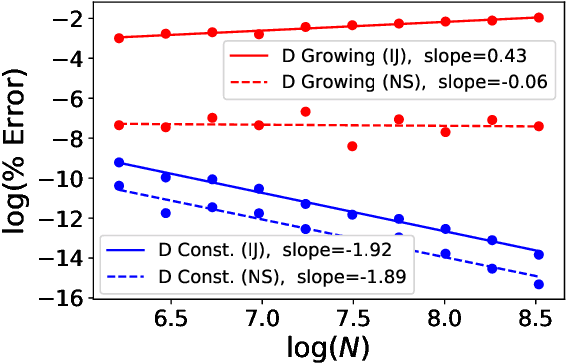
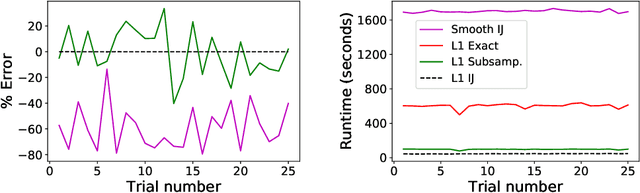
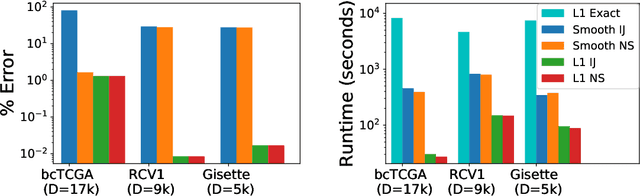
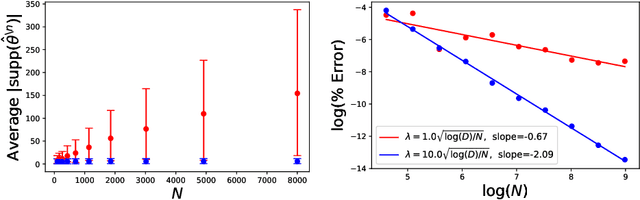
Leave-one-out cross validation (LOOCV) can be particularly accurate among CV variants for estimating out-of-sample error. Unfortunately, LOOCV requires re-fitting a model $N$ times for a dataset of size $N$. To avoid this prohibitive computational expense, a number of authors have proposed approximations to LOOCV. These approximations work well when the unknown parameter is of small, fixed dimension but suffer in high dimensions; they incur a running time roughly cubic in the dimension, and, in fact, we show their accuracy significantly deteriorates in high dimensions. We demonstrate that these difficulties can be surmounted in $\ell_1$-regularized generalized linear models when we assume that the unknown parameter, while high dimensional, has a small support. In particular, we show that, under interpretable conditions, the support of the recovered parameter does not change as each datapoint is left out. This result implies that the previously proposed heuristic of only approximating CV along the support of the recovered parameter has running time and error that scale with the (small) support size even when the full dimension is large. Experiments on synthetic and real data support the accuracy of our approximations.
Global-Local Airborne Mapping (GLAM): Reconstructing a City from Aerial Videos
Jun 07, 2018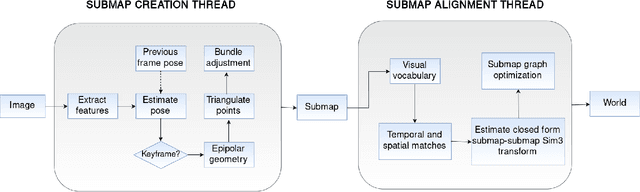
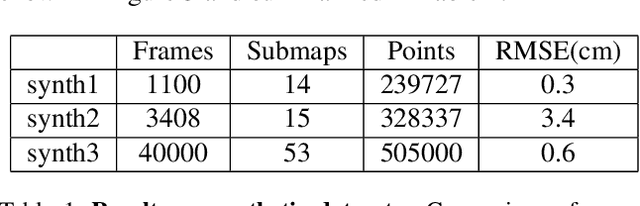

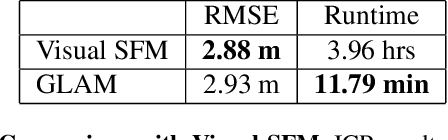
Monocular visual SLAM has become an attractive practical approach for robot localization and 3D environment mapping, since cameras are small, lightweight, inexpensive, and produce high-rate, high-resolution data streams. Although numerous robust tools have been developed, most existing systems are designed to operate in terrestrial environments and at relatively small scale (a few thousand frames) due to constraints on computation and storage. In this paper, we present a feature-based visual SLAM system for aerial video whose simple design permits near real-time operation, and whose scalability permits large-area mapping using tens of thousands of frames, all on a single conventional computer. Our approach consists of two parallel threads: the first incrementally creates small locally consistent submaps and estimates camera poses at video rate; the second aligns these submaps with one another to produce a single globally consistent map via factor graph optimization over both poses and landmarks. Scale drift is minimized through the use of 7-degree-of-freedom similarity transformations during submap alignment. We quantify our system's performance on both simulated and real data sets, and demonstrate city-scale map reconstruction accurate to within 2 meters using nearly 90,000 aerial video frames - to our knowledge, the largest and fastest such reconstruction to date.