 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Gaussian Grasp Maps for Generative Grasping Models
Jun 01, 2022
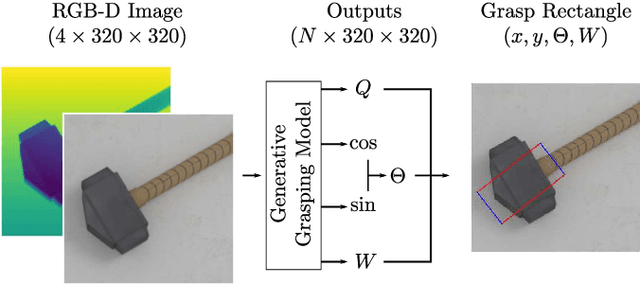
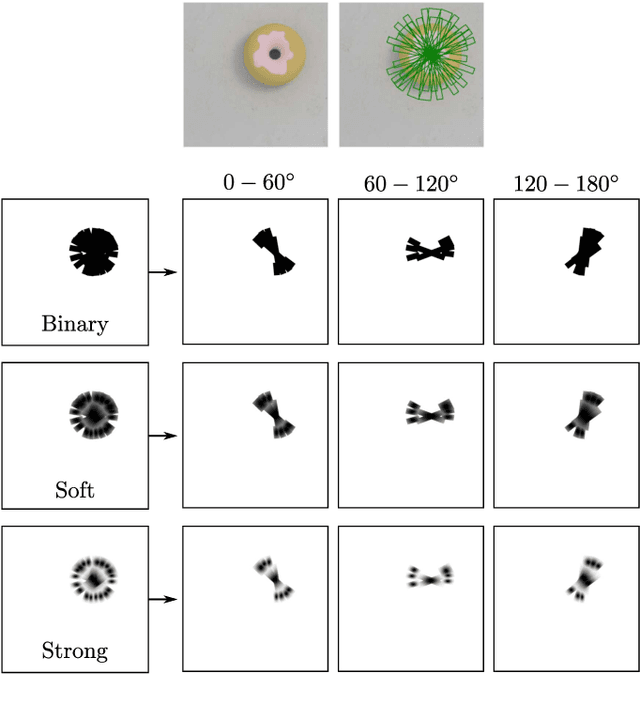

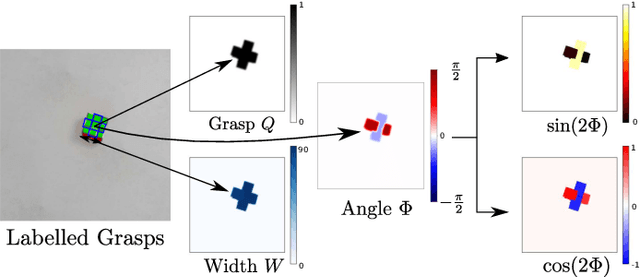
Generalising robotic grasping to previously unseen objects is a key task in general robotic manipulation. The current method for training many antipodal generative grasping models rely on a binary ground truth grasp map generated from the centre thirds of correctly labelled grasp rectangles. However, these binary maps do not accurately reflect the positions in which a robotic arm can correctly grasp a given object. We propose a continuous Gaussian representation of annotated grasps to generate ground truth training data which achieves a higher success rate on a simulated robotic grasping benchmark. Three modern generative grasping networks are trained with either binary or Gaussian grasp maps, along with recent advancements from the robotic grasping literature, such as discretisation of grasp angles into bins and an attentional loss function. Despite negligible difference according to the standard rectangle metric, Gaussian maps better reproduce the training data and therefore improve success rates when tested on the same simulated robot arm by avoiding collisions with the object: achieving 87.94\% accuracy. Furthermore, the best performing model is shown to operate with a high success rate when transferred to a real robotic arm, at high inference speeds, without the need for transfer learning. The system is then shown to be capable of performing grasps on an antagonistic physical object dataset benchmark.
Improving Robotic Grasping on Monocular Images Via Multi-Task Learning and Positional Loss
Nov 05, 2020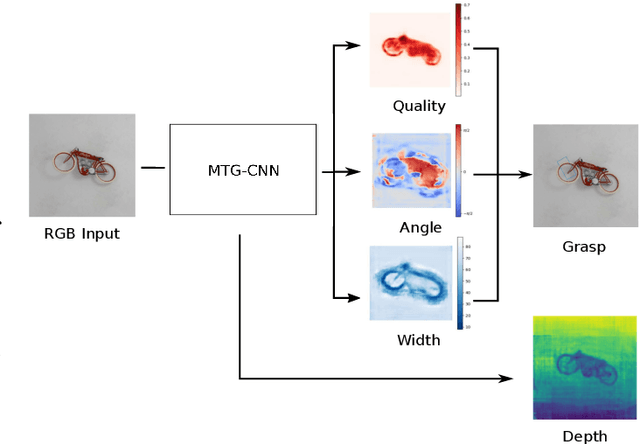
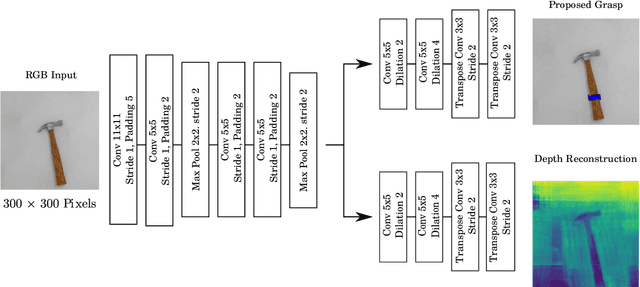
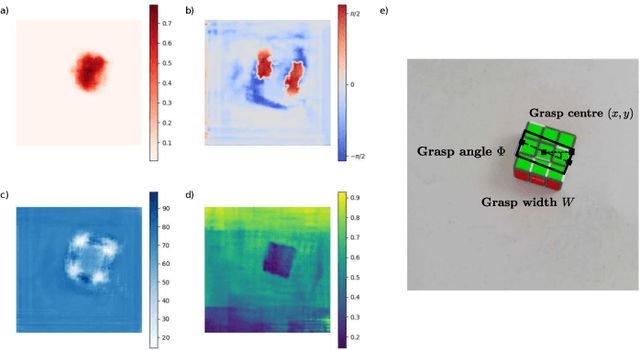
In this paper, we introduce two methods of improving real-time object grasping performance from monocular colour images in an end-to-end CNN architecture. The first is the addition of an auxiliary task during model training (multi-task learning). Our multi-task CNN model improves grasping performance from a baseline average of 72.04% to 78.14% on the large Jacquard grasping dataset when performing a supplementary depth reconstruction task. The second is introducing a positional loss function that emphasises loss per pixel for secondary parameters (gripper angle and width) only on points of an object where a successful grasp can take place. This increases performance from a baseline average of 72.04% to 78.92% as well as reducing the number of training epochs required. These methods can be also performed in tandem resulting in a further performance increase to 79.12% while maintaining sufficient inference speed to afford real-time grasp processing.