 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Time Attacks against k-Nearest Neighbors
Aug 15, 2022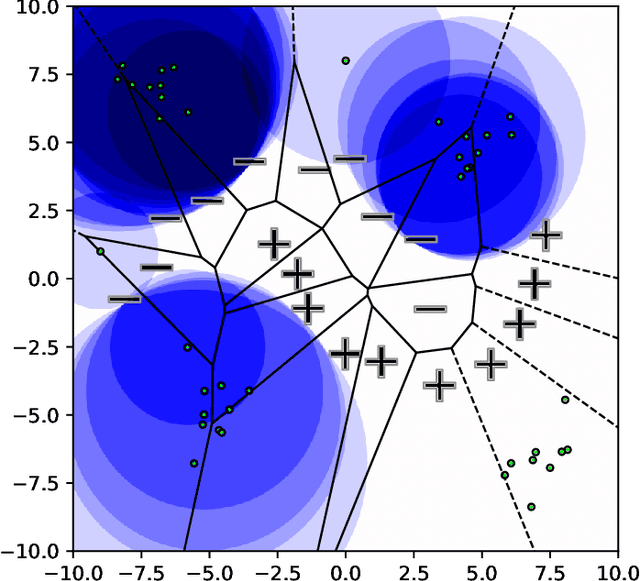
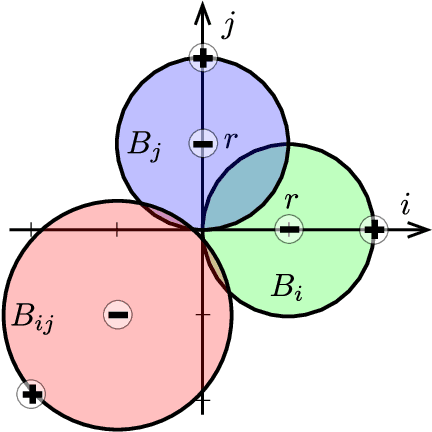
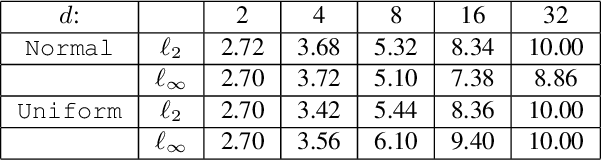
Nearest neighbor-based methods are commonly used for classification tasks and as subroutines of other data-analysis methods. An attacker with the capability of inserting their own data points into the training set can manipulate the inferred nearest neighbor structure. We distill this goal to the task of performing a training-set data insertion attack against $k$-Nearest Neighbor classification ($k$NN). We prove that computing an optimal training-time (a.k.a. poisoning) attack against $k$NN classification is NP-Hard, even when $k = 1$ and the attacker can insert only a single data point. We provide an anytime algorithm to perform such an attack, and a greedy algorithm for general $k$ and attacker budget. We provide theoretical bounds and empirically demonstrate the effectiveness and practicality of our methods on synthetic and real-world datasets. Empirically, we find that $k$NN is vulnerable in practice and that dimensionality reduction is an effective defense. We conclude with a discussion of open problems illuminated by our analysis.