 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Unified Framework for Uncertainty-aware Nonlinear Variable Selection with Theoretical Guarantees
Apr 15, 2022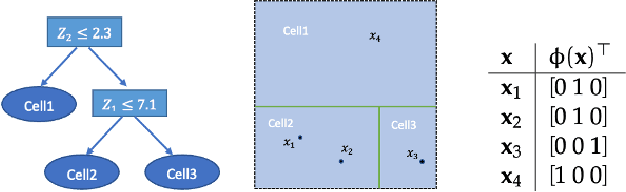
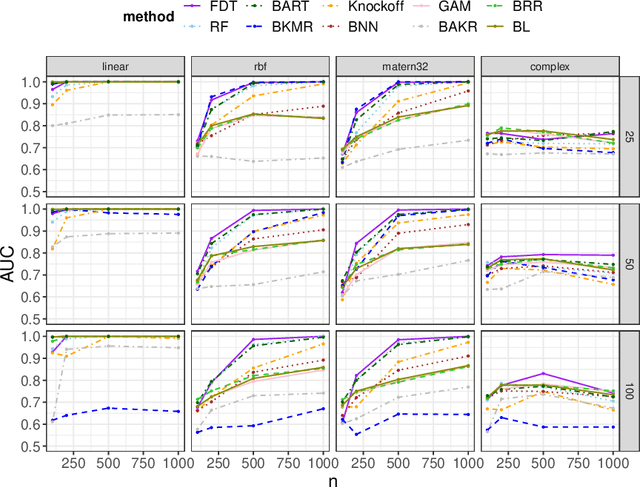
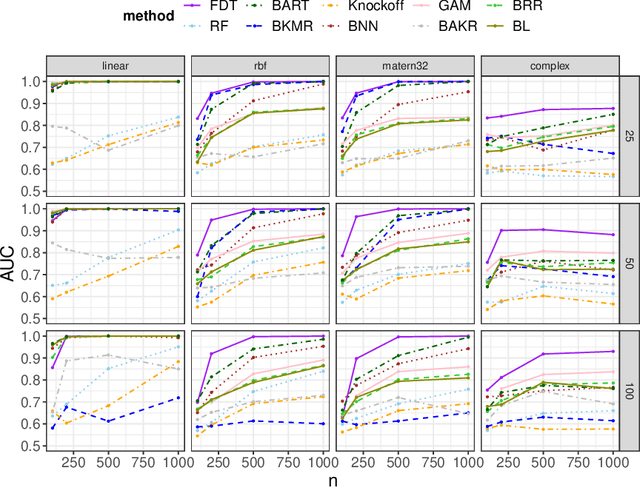
We develop a simple and unified framework for nonlinear variable selection that incorporates model uncertainty and is compatible with a wide range of machine learning models (e.g., tree ensembles, kernel methods and neural network). In particular, for a learned nonlinear model $f(\mathbf{x})$, we consider quantifying the importance of an input variable $\mathbf{x}^j$ using the integrated gradient measure $\psi_j = \Vert \frac{\partial}{\partial \mathbf{x}^j} f(\mathbf{x})\Vert^2_2$. We then (1) provide a principled approach for quantifying variable selection uncertainty by deriving its posterior distribution, and (2) show that the approach is generalizable even to non-differentiable models such as tree ensembles. Rigorous Bayesian nonparametric theorems are derived to guarantee the posterior consistency and asymptotic uncertainty of the proposed approach. Extensive simulation confirms that the proposed algorithm outperforms existing classic and recent variable selection methods.