 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Resemblance: On the Theoretical Understanding of Analogical Reasoning in Transformers
Mar 05, 2026Understanding reasoning in large language models is complicated by evaluations that conflate multiple reasoning types. We isolate analogical reasoning (inferring shared properties between entities based on known similarities) and analyze its emergence in transformers. We theoretically prove three key results: (1) Joint training on similarity and attribution premises enables analogical reasoning through aligned representations; (2) Sequential training succeeds only when similarity structure is learned before specific attributes, revealing a necessary curriculum; (3) Two-hop reasoning ($a \to b, b \to c \implies a \to c$) reduces to analogical reasoning with identity bridges ($b = b$), which must appear explicitly in training data. These results reveal a unified mechanism: transformers encode entities with similar properties into similar representations, enabling property transfer through feature alignment. Experiments with architectures up to 1.5B parameters validate our theory and demonstrate how representational geometry shapes inductive reasoning capabilities.
FISMO: Fisher-Structured Momentum-Orthogonalized Optimizer
Jan 29, 2026Training large-scale neural networks requires solving nonconvex optimization where the choice of optimizer fundamentally determines both convergence behavior and computational efficiency. While adaptive methods like Adam have long dominated practice, the recently proposed Muon optimizer achieves superior performance through orthogonalized momentum updates that enforce isotropic geometry with uniform singular values. However, this strict isotropy discards potentially valuable curvature information encoded in gradient spectra, motivating optimization methods that balance geometric structure with adaptivity. We introduce FISMO (Fisher-Structured Momentum-Orthogonalized) optimizer, which generalizes isotropic updates to incorporate anisotropic curvature information through Fisher information geometry. By reformulating the optimizer update as a trust-region problem constrained by a Kronecker-factored Fisher metric, FISMO achieves structured preconditioning that adapts to local loss landscape geometry while maintaining computational tractability. We establish convergence guarantees for FISMO in stochastic nonconvex settings, proving an $\mathcal{O}(1/\sqrt{T})$ rate for the expected squared gradient norm with explicit characterization of variance reduction through mini-batching. Empirical evaluation on image classification and language modeling benchmarks demonstrates that FISMO achieves superior training efficiency and final performance compared to established baselines.
Decentralized Multi-Task Online Convex Optimization Under Random Link Failures
Jan 04, 2024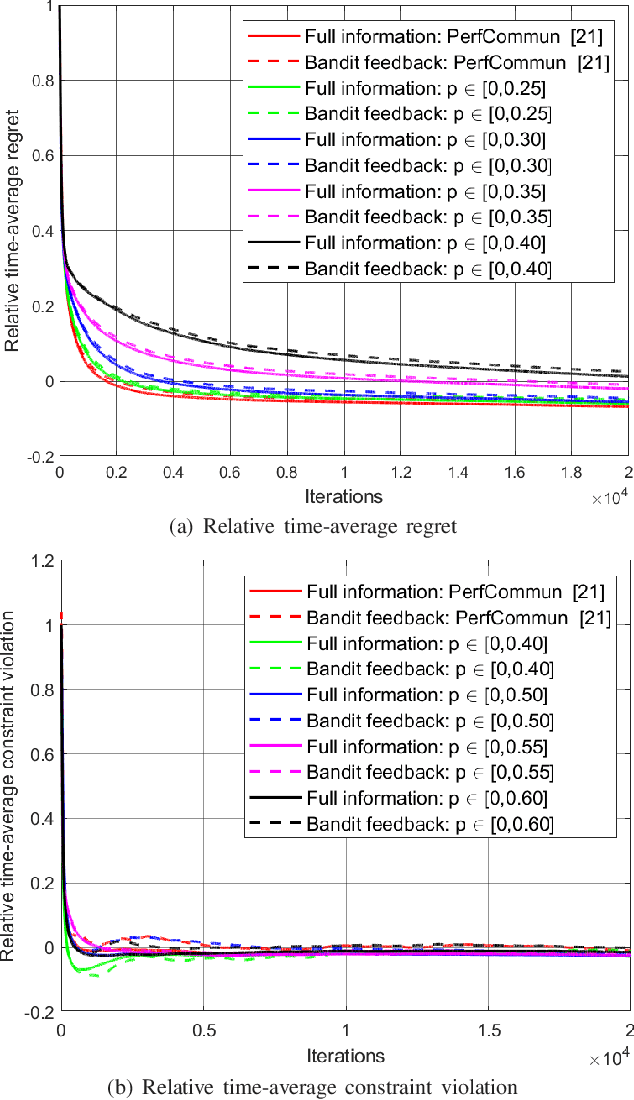
Decentralized optimization methods often entail information exchange between neighbors. Transmission failures can happen due to network congestion, hardware/software issues, communication outage, and other factors. In this paper, we investigate the random link failure problem in decentralized multi-task online convex optimization, where agents have individual decisions that are coupled with each other via pairwise constraints. Although widely used in constrained optimization, conventional saddle-point algorithms are not directly applicable here because of random packet dropping. To address this issue, we develop a robust decentralized saddle-point algorithm against random link failures with heterogeneous probabilities by replacing the missing decisions of neighbors with their latest received values. Then, by judiciously bounding the accumulated deviation stemming from this replacement, we first establish that our algorithm achieves $\mathcal{O}(\sqrt{T})$ regret and $\mathcal{O}(T^\frac{3}{4})$ constraint violations for the full information scenario, where the complete information on the local cost function is revealed to each agent at the end of each time slot. These two bounds match, in order sense, the performance bounds of algorithms with perfect communications. Further, we extend our algorithm and analysis to the two-point bandit feedback scenario, where only the values of the local cost function at two random points are disclosed to each agent sequentially. Performance bounds of the same orders as the full information case are derived. Finally, we corroborate the efficacy of the proposed algorithms and the analytical results through numerical simulations.
Zero-Regret Performative Prediction Under Inequality Constraints
Sep 22, 2023
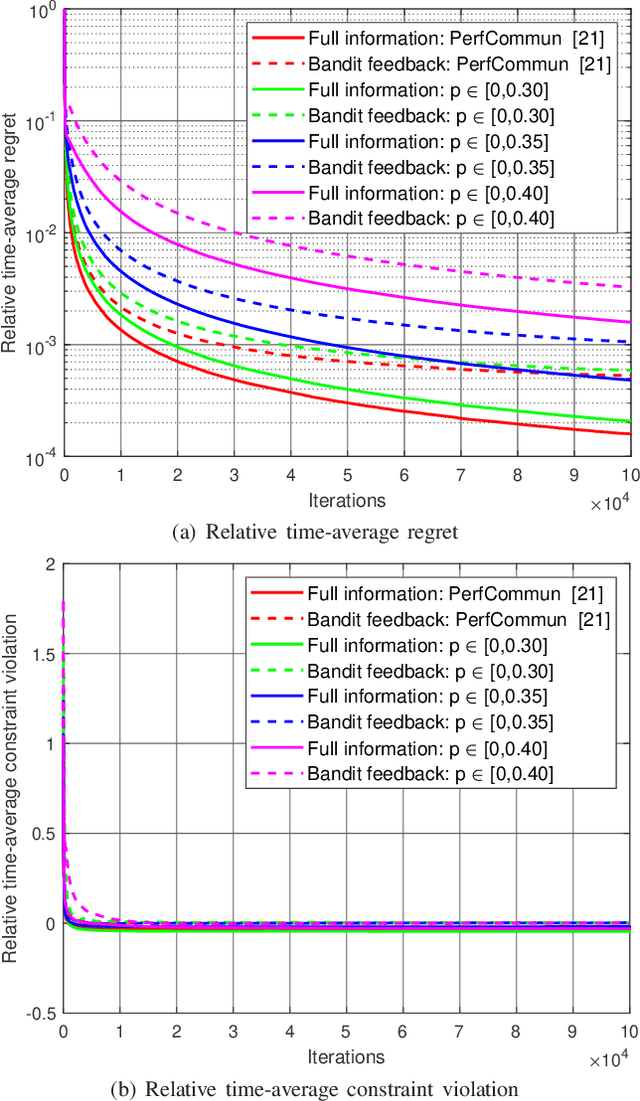
Performative prediction is a recently proposed framework where predictions guide decision-making and hence influence future data distributions. Such performative phenomena are ubiquitous in various areas, such as transportation, finance, public policy, and recommendation systems. To date, work on performative prediction has only focused on unconstrained scenarios, neglecting the fact that many real-world learning problems are subject to constraints. This paper bridges this gap by studying performative prediction under inequality constraints. Unlike most existing work that provides only performative stable points, we aim to find the optimal solutions. Anticipating performative gradients is a challenging task, due to the agnostic performative effect on data distributions. To address this issue, we first develop a robust primal-dual framework that requires only approximate gradients up to a certain accuracy, yet delivers the same order of performance as the stochastic primal-dual algorithm without performativity. Based on this framework, we then propose an adaptive primal-dual algorithm for location families. Our analysis demonstrates that the proposed adaptive primal-dual algorithm attains $\ca{O}(\sqrt{T})$ regret and constraint violations, using only $\sqrt{T} + 2T$ samples, where $T$ is the time horizon. To our best knowledge, this is the first study and analysis on the optimality of the performative prediction problem under inequality constraints. Finally, we validate the effectiveness of our algorithm and theoretical results through numerical simulations.
RAF-AU Database: In-the-Wild Facial Expressions with Subjective Emotion Judgement and Objective AU Annotations
Aug 12, 2020
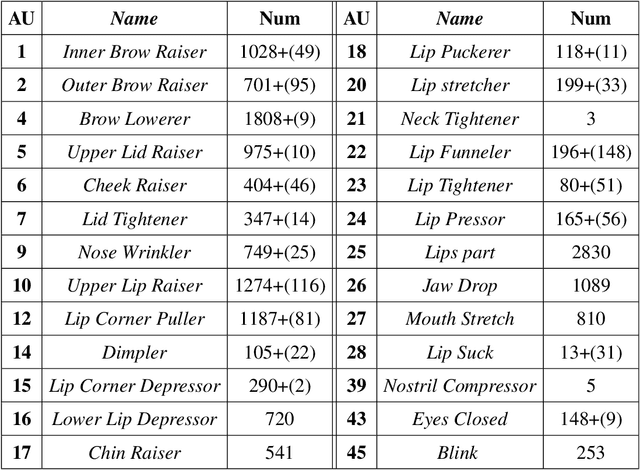

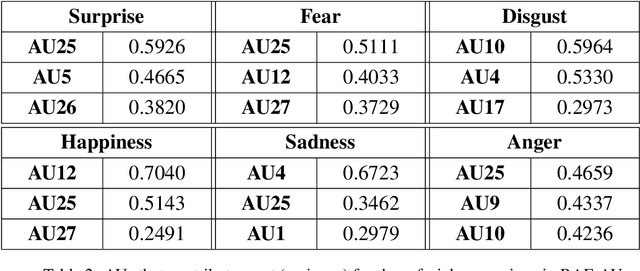
Much of the work on automatic facial expression recognition relies on databases containing a certain number of emotion classes and their exaggerated facial configurations (generally six prototypical facial expressions), based on Ekman's Basic Emotion Theory. However, recent studies have revealed that facial expressions in our human life can be blended with multiple basic emotions. And the emotion labels for these in-the-wild facial expressions cannot easily be annotated solely on pre-defined AU patterns. How to analyze the action units for such complex expressions is still an open question. To address this issue, we develop a RAF-AU database that employs a sign-based (i.e., AUs) and judgement-based (i.e., perceived emotion) approach to annotating blended facial expressions in the wild. We first reviewed the annotation methods in existing databases and identified crowdsourcing as a promising strategy for labeling in-the-wild facial expressions. Then, RAF-AU was finely annotated by experienced coders, on which we also conducted a preliminary investigation of which key AUs contribute most to a perceived emotion, and the relationship between AUs and facial expressions. Finally, we provided a baseline for AU recognition in RAF-AU using popular features and multi-label learning methods.