 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrap Deep Spectral Clustering with Optimal Transport
Aug 06, 2025Spectral clustering is a leading clustering method. Two of its major shortcomings are the disjoint optimization process and the limited representation capacity. To address these issues, we propose a deep spectral clustering model (named BootSC), which jointly learns all stages of spectral clustering -- affinity matrix construction, spectral embedding, and $k$-means clustering -- using a single network in an end-to-end manner. BootSC leverages effective and efficient optimal-transport-derived supervision to bootstrap the affinity matrix and the cluster assignment matrix. Moreover, a semantically-consistent orthogonal re-parameterization technique is introduced to orthogonalize spectral embeddings, significantly enhancing the discrimination capability. Experimental results indicate that BootSC achieves state-of-the-art clustering performance. For example, it accomplishes a notable 16\% NMI improvement over the runner-up method on the challenging ImageNet-Dogs dataset. Our code is available at https://github.com/spdj2271/BootSC.
Deep Spectral Clustering via Joint Spectral Embedding and Kmeans
Dec 15, 2024



Spectral clustering is a popular clustering method. It first maps data into the spectral embedding space and then uses Kmeans to find clusters. However, the two decoupled steps prohibit joint optimization for the optimal solution. In addition, it needs to construct the similarity graph for samples, which suffers from the curse of dimensionality when the data are high-dimensional. To address these two challenges, we introduce \textbf{D}eep \textbf{S}pectral \textbf{C}lustering (\textbf{DSC}), which consists of two main modules: the spectral embedding module and the greedy Kmeans module. The former module learns to efficiently embed raw samples into the spectral embedding space using deep neural networks and power iteration. The latter module improves the cluster structures of Kmeans on the learned spectral embeddings by a greedy optimization strategy, which iteratively reveals the direction of the worst cluster structures and optimizes embeddings in this direction. To jointly optimize spectral embeddings and clustering, we seamlessly integrate the two modules and optimize them in an end-to-end manner. Experimental results on seven real-world datasets demonstrate that DSC achieves state-of-the-art clustering performance.
PICNN: A Pathway towards Interpretable Convolutional Neural Networks
Dec 19, 2023Convolutional Neural Networks (CNNs) have exhibited great performance in discriminative feature learning for complex visual tasks. Besides discrimination power, interpretability is another important yet under-explored property for CNNs. One difficulty in the CNN interpretability is that filters and image classes are entangled. In this paper, we introduce a novel pathway to alleviate the entanglement between filters and image classes. The proposed pathway groups the filters in a late conv-layer of CNN into class-specific clusters. Clusters and classes are in a one-to-one relationship. Specifically, we use the Bernoulli sampling to generate the filter-cluster assignment matrix from a learnable filter-class correspondence matrix. To enable end-to-end optimization, we develop a novel reparameterization trick for handling the non-differentiable Bernoulli sampling. We evaluate the effectiveness of our method on ten widely used network architectures (including nine CNNs and a ViT) and five benchmark datasets. Experimental results have demonstrated that our method PICNN (the combination of standard CNNs with our proposed pathway) exhibits greater interpretability than standard CNNs while achieving higher or comparable discrimination power.
Deep Embedded K-Means Clustering
Sep 30, 2021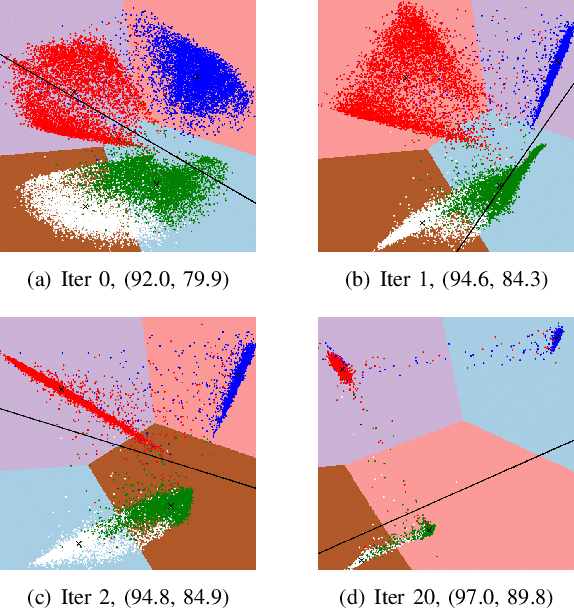


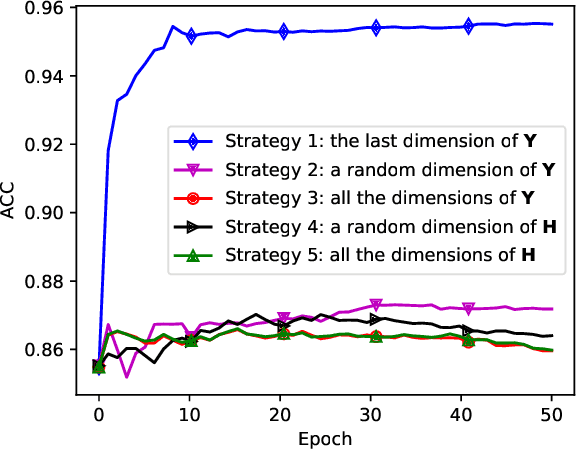
Recently, deep clustering methods have gained momentum because of the high representational power of deep neural networks (DNNs) such as autoencoder. The key idea is that representation learning and clustering can reinforce each other: Good representations lead to good clustering while good clustering provides good supervisory signals to representation learning. Critical questions include: 1) How to optimize representation learning and clustering? 2) Should the reconstruction loss of autoencoder be considered always? In this paper, we propose DEKM (for Deep Embedded K-Means) to answer these two questions. Since the embedding space generated by autoencoder may have no obvious cluster structures, we propose to further transform the embedding space to a new space that reveals the cluster-structure information. This is achieved by an orthonormal transformation matrix, which contains the eigenvectors of the within-class scatter matrix of K-means. The eigenvalues indicate the importance of the eigenvectors' contributions to the cluster-structure information in the new space. Our goal is to increase the cluster-structure information. To this end, we discard the decoder and propose a greedy method to optimize the representation. Representation learning and clustering are alternately optimized by DEKM. Experimental results on the real-world datasets demonstrate that DEKM achieves state-of-the-art performance.