 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXKV: Personalized KV Cache Memory Reduction for Long-Context LLM Inference
Dec 08, 2024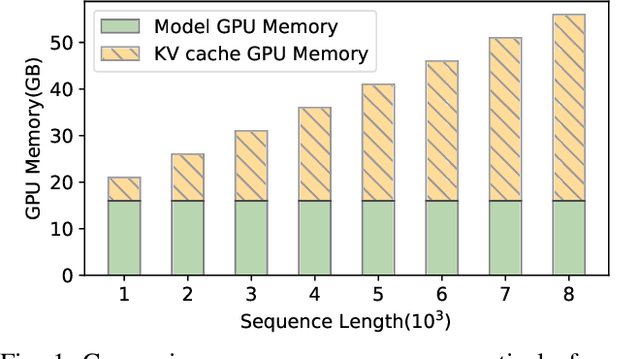



Recently the generative Large Language Model (LLM) has achieved remarkable success in numerous applications. Notably its inference generates output tokens one-by-one, leading to many redundant computations. The widely-used KV-Cache framework makes a compromise between time and space complexities. However, caching data generates the increasingly growing memory demand, that can quickly exhaust the limited memory capacity of the modern accelerator like GPUs, particularly in long-context inference tasks. Existing studies reduce memory consumption by evicting some of cached data that have less important impact on inference accuracy. But the benefit in practice is far from ideal due to the static cache allocation across different LLM network layers. This paper observes that the layer-specific cached data have very different impacts on accuracy. We quantify this difference, and give experimental and theoretical validation. We accordingly make a formal analysis and shows that customizing the cache size for each layer in a personalized manner can yield a significant memory reduction, while still providing comparable accuracy. We simulate the cache allocation as a combinatorial optimization problem and give a global optimal solution. In particular, we devise a mini- and sampling-based inference over a lightweight variant of the LLM model, so as to quickly capture the difference and then feed it into the personalized algorithms. Extensive experiments on real-world datasets demonstrate that our proposals can reduce KV cache memory consumption by 61.6% on average, improve computational efficiency by 2.1x and then increase the throughput by up to 5.5x.