 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeClaw: A Time-Series AI Agent with Exploratory Execution Learning
May 11, 2026Time series analysis underpins forecasting, monitoring, and decision making in domains such as finance and weather, where solving a task often requires both numerical accuracy and contextual reasoning. Recent progress has moved from specialized neural predictors to approaches built on LLMs and foundation models that can reason over time series inputs and use external tools. However, most such systems remain execution-centric: they focus on solving the current instance but learn little from exploratory execution. This is especially limiting in verifiable numeric settings, where multiple candidate executions and tool-use procedures may all be task-valid yet differ sharply in quantitative quality, and where early success can trigger tool-prior collapse that suppresses further exploration. To address this limitation, we present TimeClaw, an exploratory execution learning framework that turns exploratory execution into reusable hierarchical distilled experience through a four-stage loop: Explore, Compare, Distill, and Reinject. TimeClaw combines metric-supervised exploratory execution learning, task-aware tool dropout, and hierarchical distilled experience for inference-time reinjection, while keeping the base model frozen and avoiding online test-time adaptation. In an MTBench-aligned evaluation with 17 tasks that span finance and weather prediction and reasoning tasks, TimeClaw delivers consistent gains over the baselines. These results suggest that, for scientific systems, the bottleneck is not only execution-time capability, but how exploratory experience is compared, distilled, and reused.
Non-stationary Diffusion For Probabilistic Time Series Forecasting
May 07, 2025



Due to the dynamics of underlying physics and external influences, the uncertainty of time series often varies over time. However, existing Denoising Diffusion Probabilistic Models (DDPMs) often fail to capture this non-stationary nature, constrained by their constant variance assumption from the additive noise model (ANM). In this paper, we innovatively utilize the Location-Scale Noise Model (LSNM) to relax the fixed uncertainty assumption of ANM. A diffusion-based probabilistic forecasting framework, termed Non-stationary Diffusion (NsDiff), is designed based on LSNM that is capable of modeling the changing pattern of uncertainty. Specifically, NsDiff combines a denoising diffusion-based conditional generative model with a pre-trained conditional mean and variance estimator, enabling adaptive endpoint distribution modeling. Furthermore, we propose an uncertainty-aware noise schedule, which dynamically adjusts the noise levels to accurately reflect the data uncertainty at each step and integrates the time-varying variances into the diffusion process. Extensive experiments conducted on nine real-world and synthetic datasets demonstrate the superior performance of NsDiff compared to existing approaches. Code is available at https://github.com/wwy155/NsDiff.
Frequency Adaptive Normalization For Non-stationary Time Series Forecasting
Sep 30, 2024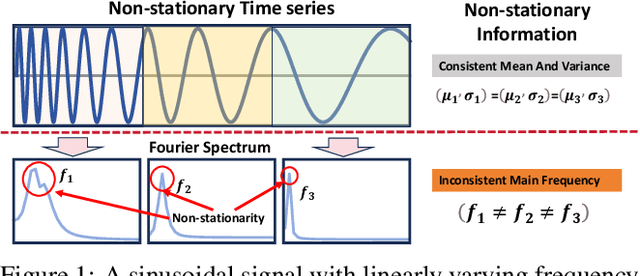

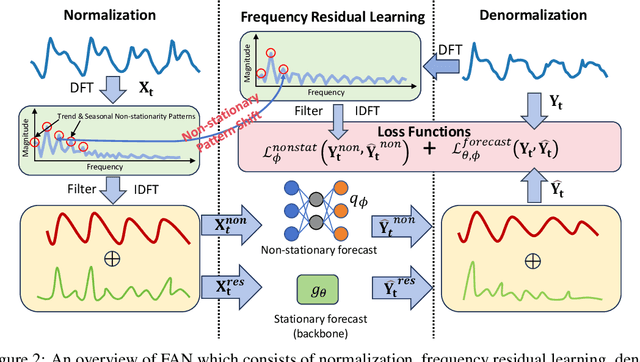
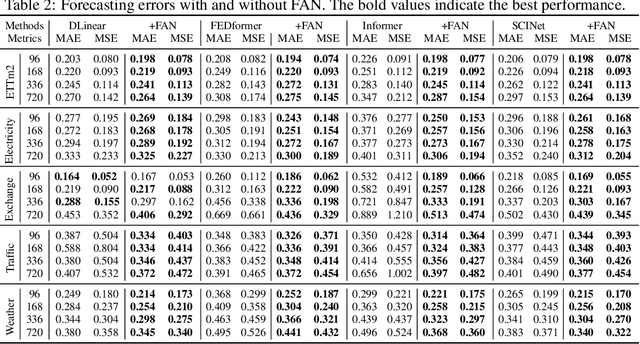
Time series forecasting typically needs to address non-stationary data with evolving trend and seasonal patterns. To address the non-stationarity, reversible instance normalization has been recently proposed to alleviate impacts from the trend with certain statistical measures, e.g., mean and variance. Although they demonstrate improved predictive accuracy, they are limited to expressing basic trends and are incapable of handling seasonal patterns. To address this limitation, this paper proposes a new instance normalization solution, called frequency adaptive normalization (FAN), which extends instance normalization in handling both dynamic trend and seasonal patterns. Specifically, we employ the Fourier transform to identify instance-wise predominant frequent components that cover most non-stationary factors. Furthermore, the discrepancy of those frequency components between inputs and outputs is explicitly modeled as a prediction task with a simple MLP model. FAN is a model-agnostic method that can be applied to arbitrary predictive backbones. We instantiate FAN on four widely used forecasting models as the backbone and evaluate their prediction performance improvements on eight benchmark datasets. FAN demonstrates significant performance advancement, achieving 7.76% ~ 37.90% average improvements in MSE.
Data Imputation with Iterative Graph Reconstruction
Dec 06, 2022



Effective data imputation demands rich latent ``structure" discovery capabilities from ``plain" tabular data. Recent advances in graph neural networks-based data imputation solutions show their strong structure learning potential by directly translating tabular data as bipartite graphs. However, due to a lack of relations between samples, those solutions treat all samples equally which is against one important observation: ``similar sample should give more information about missing values." This paper presents a novel Iterative graph Generation and Reconstruction framework for Missing data imputation(IGRM). Instead of treating all samples equally, we introduce the concept: ``friend networks" to represent different relations among samples. To generate an accurate friend network with missing data, an end-to-end friend network reconstruction solution is designed to allow for continuous friend network optimization during imputation learning. The representation of the optimized friend network, in turn, is used to further optimize the data imputation process with differentiated message passing. Experiment results on eight benchmark datasets show that IGRM yields 39.13% lower mean absolute error compared with nine baselines and 9.04% lower than the second-best.