 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Culture to Clothing: Discovering the World Events Behind A Century of Fashion Images
Feb 02, 2021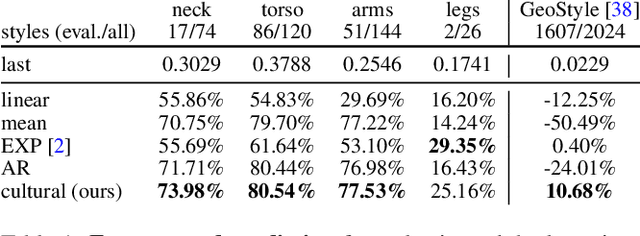
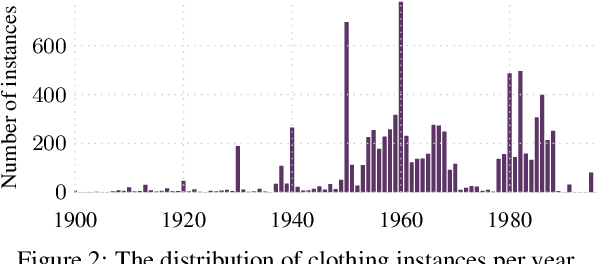


Fashion is intertwined with external cultural factors, but identifying these links remains a manual process limited to only the most salient phenomena. We propose a data-driven approach to identify specific cultural factors affecting the clothes people wear. Using large-scale datasets of news articles and vintage photos spanning a century, we introduce a multi-modal statistical model to detect influence relationships between happenings in the world and people's choice of clothing. Furthermore, we apply our model to improve the concrete vision tasks of visual style forecasting and photo timestamping on two datasets. Our work is a first step towards a computational, scalable, and easily refreshable approach to link culture to clothing.
Learning Patterns of Tourist Movement and Photography from Geotagged Photos at Archaeological Heritage Sites in Cuzco, Peru
Jun 29, 2020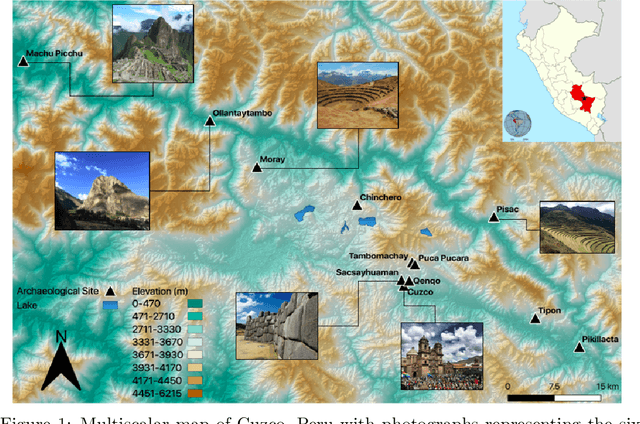

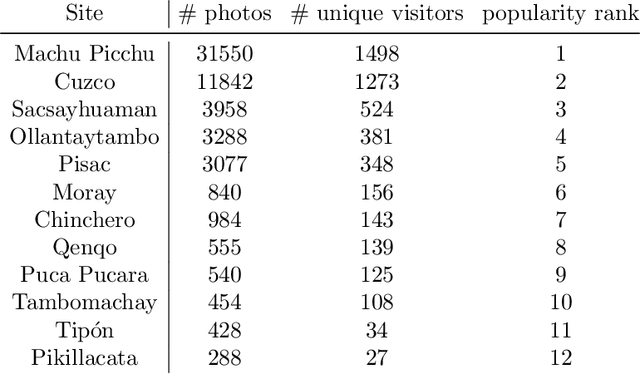
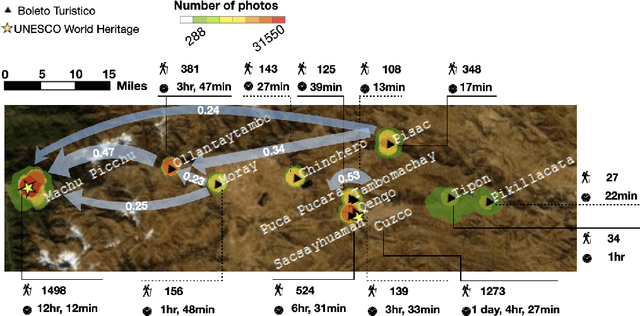
The popularity of media sharing platforms in recent decades has provided an abundance of open source data that remains underutilized by heritage scholars. By pairing geotagged internet photographs with machine learning and computer vision algorithms, we build upon the current theoretical discourse of anthropology associated with visuality and heritage tourism to identify travel patterns across a known archaeological heritage circuit, and quantify visual culture and experiences in Cuzco, Peru. Leveraging large-scale in-the-wild tourist photos, our goals are to (1) understand how the intensification of tourism intersects with heritage regulations and social media, aiding in the articulation of travel patterns across Cuzco's heritage landscape; and to (2) assess how aesthetic preferences and visuality become entangled with the rapidly evolving expectations of tourists, whose travel narratives are curated on social media and grounded in historic site representations.
Dressing for Diverse Body Shapes
Dec 13, 2019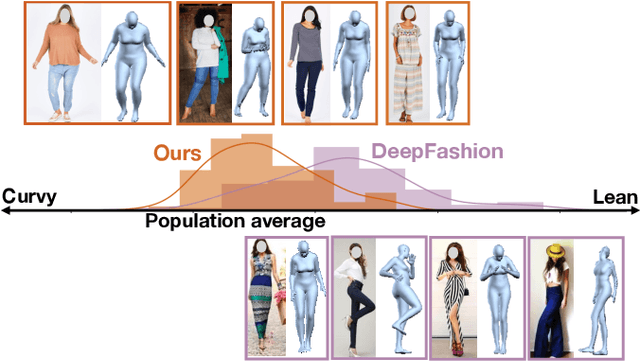
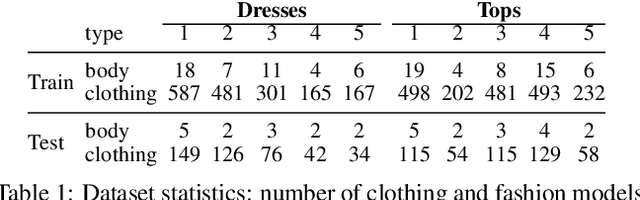

Body shape plays an important role in determining what garments will best suit a given person, yet today's clothing recommendation methods take a "one shape fits all" approach. These body-agnostic vision methods and datasets are a barrier to inclusion, ill-equipped to provide good suggestions for diverse body shapes. We introduce ViBE, a VIsual Body-aware Embedding that captures clothing's affinity with different body shapes. Given an image of a person, the proposed multi-view embedding identifies garments that will flatter her specific body shape. We show how to learn the embedding from an online catalog displaying fashion models of various shapes and sizes wearing the products, and we devise a method to explain the algorithm's suggestions for well-fitting garments. We apply our approach to a dataset of diverse subjects, and demonstrate its strong advantages over the status quo body-agnostic recommendation, both according to automated metrics and human opinion.
Fashion++: Minimal Edits for Outfit Improvement
Apr 19, 2019

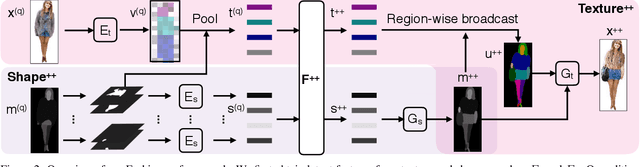
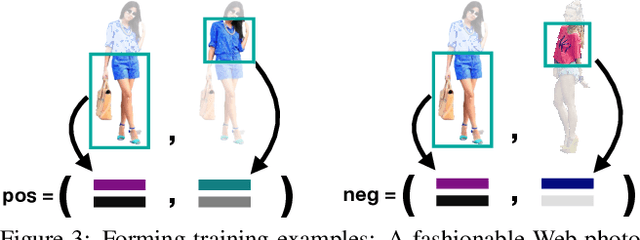
Given an outfit, what small changes would most improve its fashionability? This question presents an intriguing new vision challenge. We introduce Fashion++, an approach that proposes minimal adjustments to a full-body clothing outfit that will have maximal impact on its fashionability. Our model consists of a deep image generation neural network that learns to synthesize clothing conditioned on learned per-garment encodings. The latent encodings are explicitly factorized according to shape and texture, thereby allowing direct edits for both fit/presentation and color/patterns/material, respectively. We show how to bootstrap Web photos to automatically train a fashionability model, and develop an activation maximization-style approach to transform the input image into its more fashionable self. The edits suggested range from swapping in a new garment to tweaking its color, how it is worn (e.g., rolling up sleeves), or its fit (e.g., making pants baggier). Experiments demonstrate that Fashion++ provides successful edits, both according to automated metrics and human opinion. Project page is at http://vision.cs.utexas.edu/projects/FashionPlus.
Creating Capsule Wardrobes from Fashion Images
Apr 14, 2018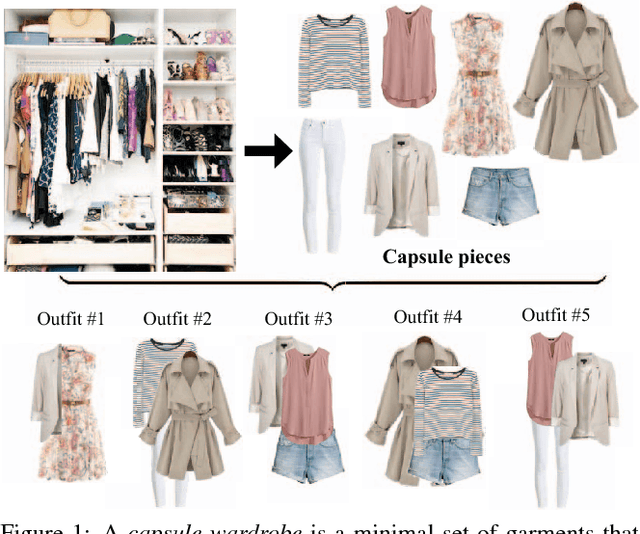



We propose to automatically create capsule wardrobes. Given an inventory of candidate garments and accessories, the algorithm must assemble a minimal set of items that provides maximal mix-and-match outfits. We pose the task as a subset selection problem. To permit efficient subset selection over the space of all outfit combinations, we develop submodular objective functions capturing the key ingredients of visual compatibility, versatility, and user-specific preference. Since adding garments to a capsule only expands its possible outfits, we devise an iterative approach to allow near-optimal submodular function maximization. Finally, we present an unsupervised approach to learn visual compatibility from "in the wild" full body outfit photos; the compatibility metric translates well to cleaner catalog photos and improves over existing methods. Our results on thousands of pieces from popular fashion websites show that automatic capsule creation has potential to mimic skilled fashionistas in assembling flexible wardrobes, while being significantly more scalable.
Learning the Latent "Look": Unsupervised Discovery of a Style-Coherent Embedding from Fashion Images
Aug 03, 2017
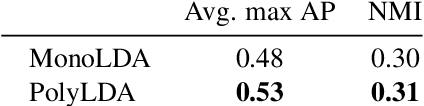
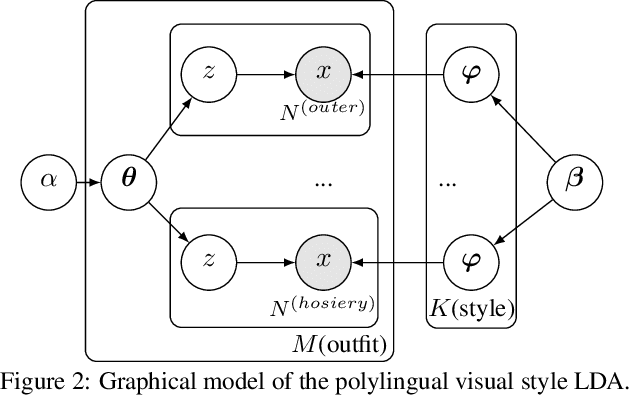
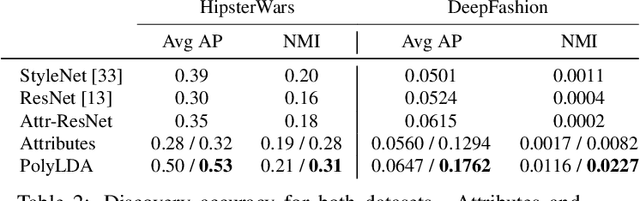
What defines a visual style? Fashion styles emerge organically from how people assemble outfits of clothing, making them difficult to pin down with a computational model. Low-level visual similarity can be too specific to detect stylistically similar images, while manually crafted style categories can be too abstract to capture subtle style differences. We propose an unsupervised approach to learn a style-coherent representation. Our method leverages probabilistic polylingual topic models based on visual attributes to discover a set of latent style factors. Given a collection of unlabeled fashion images, our approach mines for the latent styles, then summarizes outfits by how they mix those styles. Our approach can organize galleries of outfits by style without requiring any style labels. Experiments on over 100K images demonstrate its promise for retrieving, mixing, and summarizing fashion images by their style.