 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic text summarization: What has been done and what has to be done
Apr 01, 2019

Summaries are important when it comes to process huge amounts of information. Their most important benefit is saving time, which we do not have much nowadays. Therefore, a summary must be short, representative and readable. Generating summaries automatically can be beneficial for humans, since it can save time and help selecting relevant documents. Automatic summarization and, in particular, Automatic text summarization (ATS) is not a new research field; It was known since the 50s. Since then, researchers have been active to find the perfect summarization method. In this article, we will discuss different works in automatic summarization, especially the recent ones. We will present some problems and limits which prevent works to move forward. Most of these challenges are much more related to the nature of processed languages. These challenges are interesting for academics and developers, as a path to follow in this field.
Degraded Historical Documents Images Binarization Using a Combination of Enhanced Techniques
Jan 27, 2019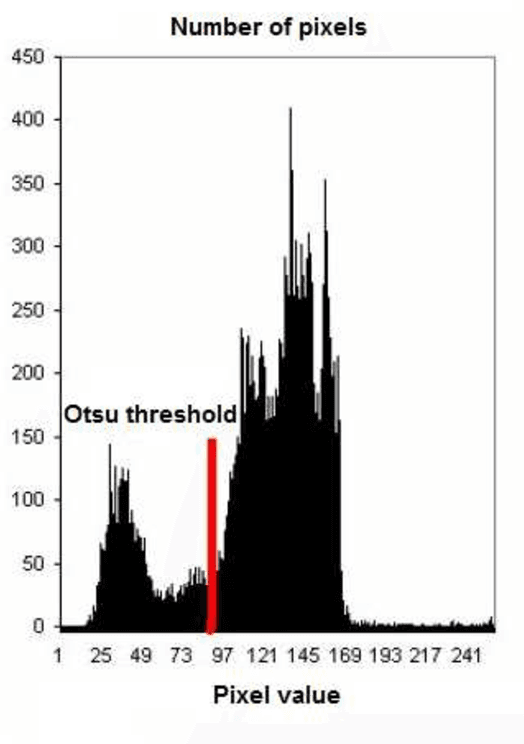
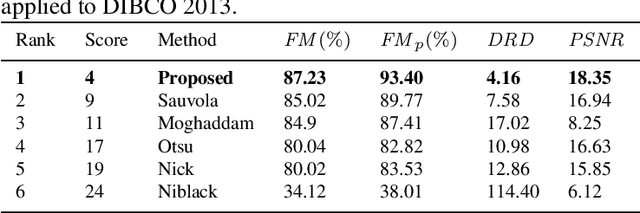
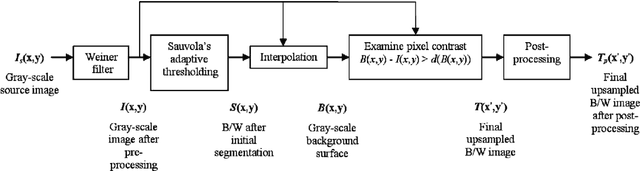
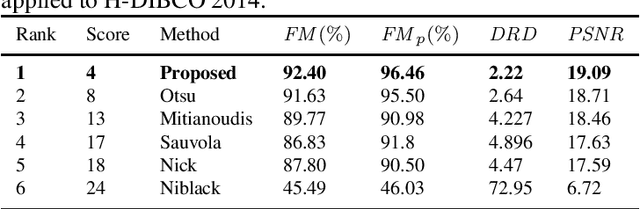
Document image binarization is the initial step and a crucial in many document analysis and recognition scheme. In fact, it is still a relevant research subject and a fundamental challenge due to its importance and influence. This paper provides an original multi-phases system that hybridizes various efficient image thresholding methods in order to get the best binarization output. First, to improve contrast in particularly defective images, the application of CLAHE algorithm is suggested and justified. We then use a cooperative technique to segment image into two separated classes. At the end, a special transformation is applied for the purpose of removing scattered noise and of correcting characters forms. Experimentations demonstrate the precision and the robustness of our framework applied on historical degraded documents images within three benchmarks compared to other noted methods.
Sentence Object Notation: Multilingual sentence notation based on Wordnet
Jan 10, 2018
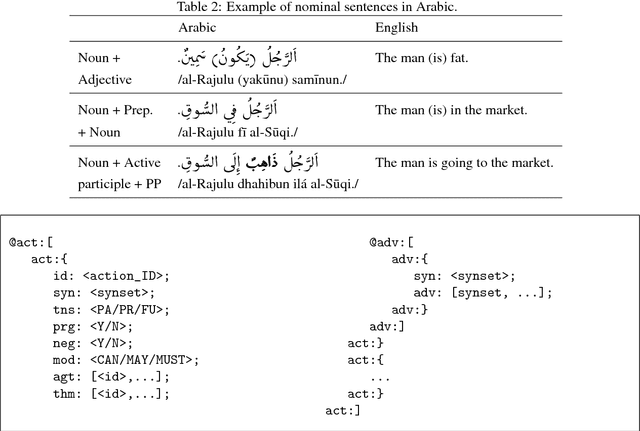


The representation of sentences is a very important task. It can be used as a way to exchange data inter-applications. One main characteristic, that a notation must have, is a minimal size and a representative form. This can reduce the transfer time, and hopefully the processing time as well. Usually, sentence representation is associated to the processed language. The grammar of this language affects how we represent the sentence. To avoid language-dependent notations, we have to come up with a new representation which don't use words, but their meanings. This can be done using a lexicon like wordnet, instead of words we use their synsets. As for syntactic relations, they have to be universal as much as possible. Our new notation is called STON "SenTences Object Notation", which somehow has similarities to JSON. It is meant to be minimal, representative and language-independent syntactic representation. Also, we want it to be readable and easy to be created. This simplifies developing simple automatic generators and creating test banks manually. Its benefit is to be used as a medium between different parts of applications like: text summarization, language translation, etc. The notation is based on 4 languages: Arabic, English, Franch and Japanese; and there are some cases where these languages don't agree on one representation. Also, given the diversity of grammatical structure of different world languages, this annotation may fail for some languages which allows more future improvements.