 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence Object Notation: Multilingual sentence notation based on Wordnet
Paper and Code
Jan 10, 2018
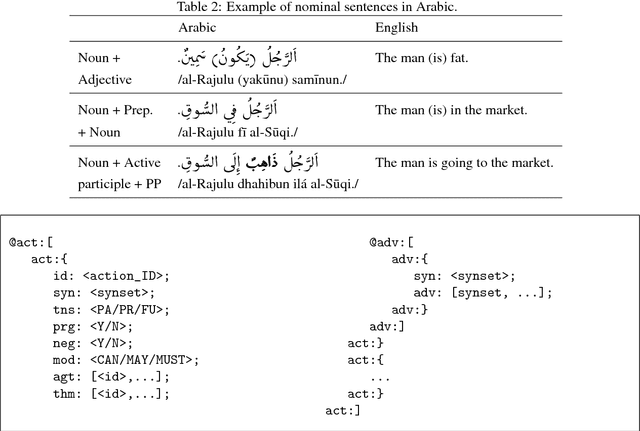


The representation of sentences is a very important task. It can be used as a way to exchange data inter-applications. One main characteristic, that a notation must have, is a minimal size and a representative form. This can reduce the transfer time, and hopefully the processing time as well. Usually, sentence representation is associated to the processed language. The grammar of this language affects how we represent the sentence. To avoid language-dependent notations, we have to come up with a new representation which don't use words, but their meanings. This can be done using a lexicon like wordnet, instead of words we use their synsets. As for syntactic relations, they have to be universal as much as possible. Our new notation is called STON "SenTences Object Notation", which somehow has similarities to JSON. It is meant to be minimal, representative and language-independent syntactic representation. Also, we want it to be readable and easy to be created. This simplifies developing simple automatic generators and creating test banks manually. Its benefit is to be used as a medium between different parts of applications like: text summarization, language translation, etc. The notation is based on 4 languages: Arabic, English, Franch and Japanese; and there are some cases where these languages don't agree on one representation. Also, given the diversity of grammatical structure of different world languages, this annotation may fail for some languages which allows more future improvements.