 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetrics and methods for a systematic comparison of fairness-aware machine learning algorithms
Oct 08, 2020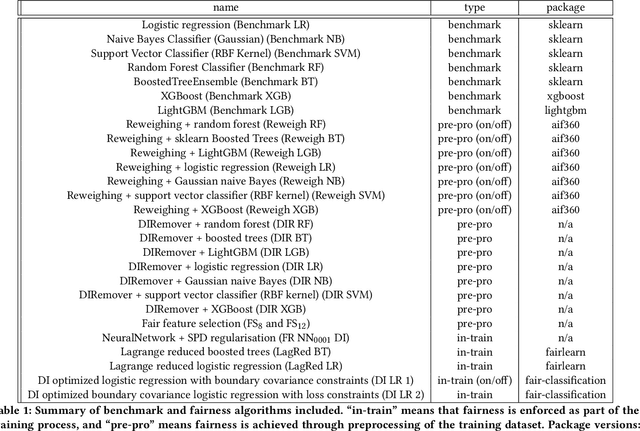
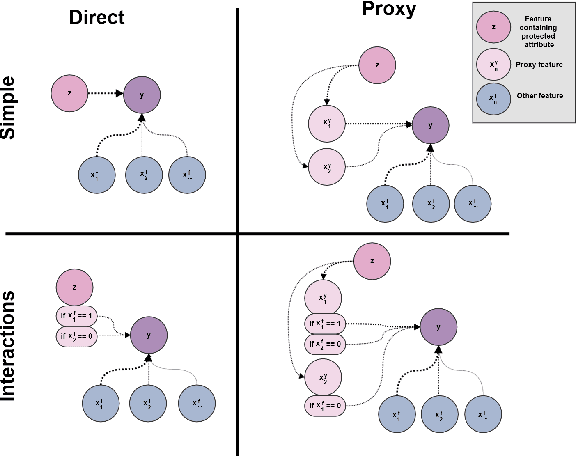
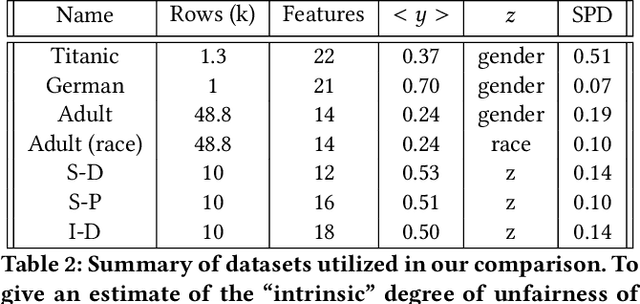
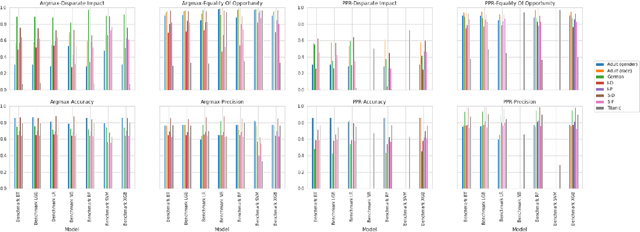
Understanding and removing bias from the decisions made by machine learning models is essential to avoid discrimination against unprivileged groups. Despite recent progress in algorithmic fairness, there is still no clear answer as to which bias-mitigation approaches are most effective. Evaluation strategies are typically use-case specific, rely on data with unclear bias, and employ a fixed policy to convert model outputs to decision outcomes. To address these problems, we performed a systematic comparison of a number of popular fairness algorithms applicable to supervised classification. Our study is the most comprehensive of its kind. It utilizes three real and four synthetic datasets, and two different ways of converting model outputs to decisions. It considers fairness, predictive-performance, calibration quality, and speed of 28 different modelling pipelines, corresponding to both fairness-unaware and fairness-aware algorithms. We found that fairness-unaware algorithms typically fail to produce adequately fair models and that the simplest algorithms are not necessarily the fairest ones. We also found that fairness-aware algorithms can induce fairness without material drops in predictive power. Finally, we found that dataset idiosyncracies (e.g., degree of intrinsic unfairness, nature of correlations) do affect the performance of fairness-aware approaches. Our results allow the practitioner to narrow down the approach(es) they would like to adopt without having to know in advance their fairness requirements.
Fairness by Explicability and Adversarial SHAP Learning
Mar 12, 2020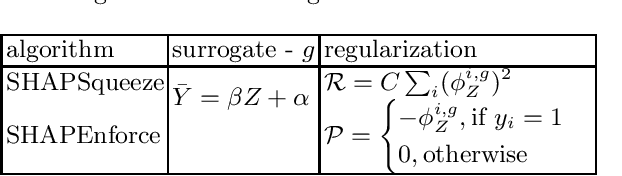
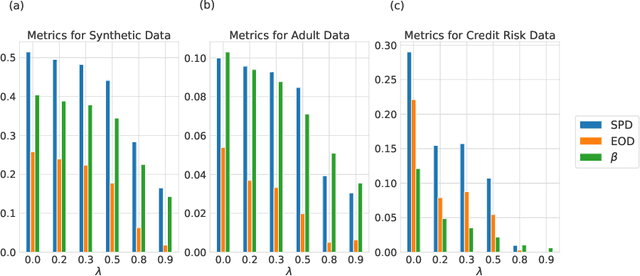
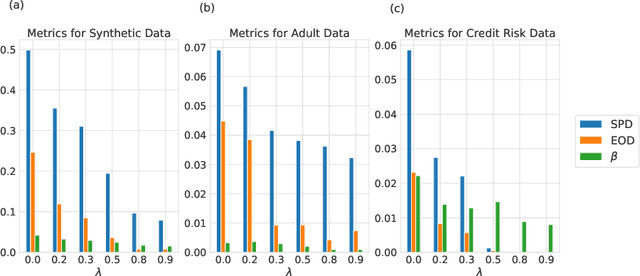
The ability to understand and trust the fairness of model predictions, particularly when considering the outcomes of unprivileged groups, is critical to the deployment and adoption of machine learning systems. SHAP values provide a unified framework for interpreting model predictions and feature attribution but do not address the problem of fairness directly. In this work, we propose a new definition of fairness that emphasises the role of an external auditor and model explicability. To satisfy this definition, we develop a framework for mitigating model bias using regularizations constructed from the SHAP values of an adversarial surrogate model. We focus on the binary classification task with a single unprivileged group and link our fairness explicability constraints to classical statistical fairness metrics. We demonstrate our approaches using gradient and adaptive boosting on: a synthetic dataset, the UCI Adult (Census) dataset and a real-world credit scoring dataset. The models produced were fairer and performant.
Counterfactual fairness: removing direct effects through regularization
Feb 26, 2020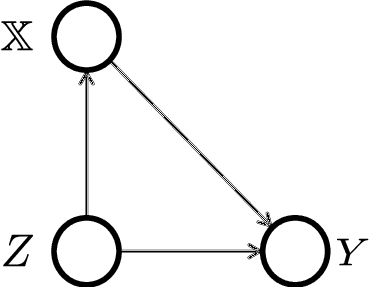
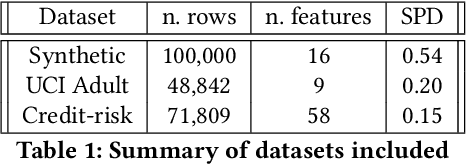
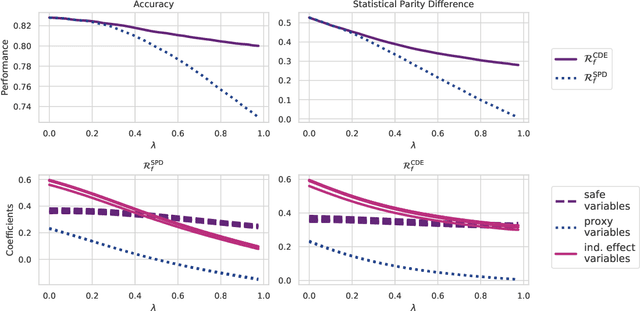
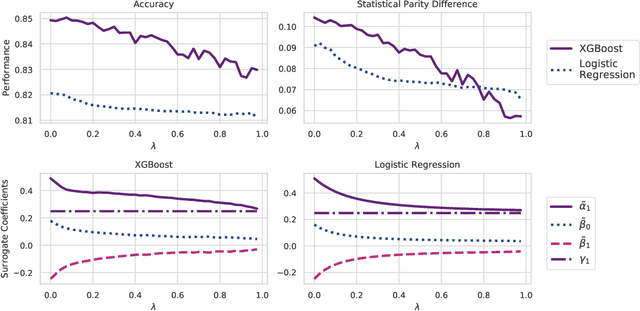
Building machine learning models that are fair with respect to an unprivileged group is a topical problem. Modern fairness-aware algorithms often ignore causal effects and enforce fairness through modifications applicable to only a subset of machine learning models. In this work, we propose a new definition of fairness that incorporates causality through the Controlled Direct Effect (CDE). We develop regularizations to tackle classical fairness measures and present a causal regularization that satisfies our new fairness definition by removing the impact of unprivileged group variables on the model outcomes as measured by the CDE. These regularizations are applicable to any model trained using by iteratively minimizing a loss through differentiation. We demonstrate our approaches using both gradient boosting and logistic regression on: a synthetic dataset, the UCI Adult (Census) Dataset, and a real-world credit-risk dataset. Our results were found to mitigate unfairness from the predictions with small reductions in model performance.