 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetrics and methods for a systematic comparison of fairness-aware machine learning algorithms
Oct 08, 2020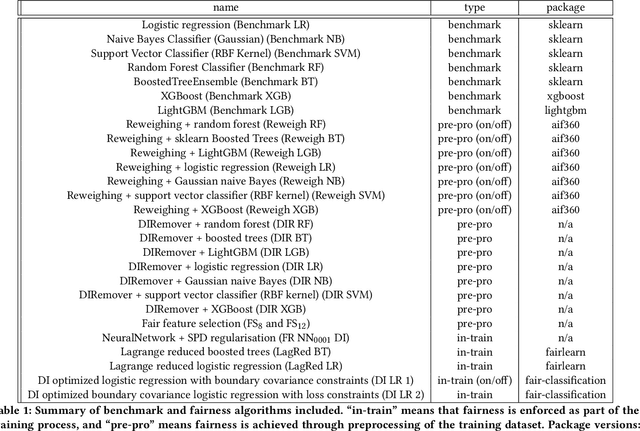
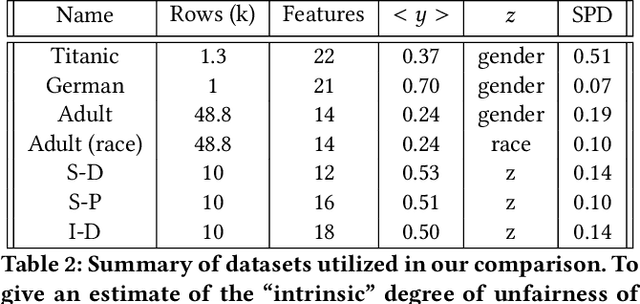
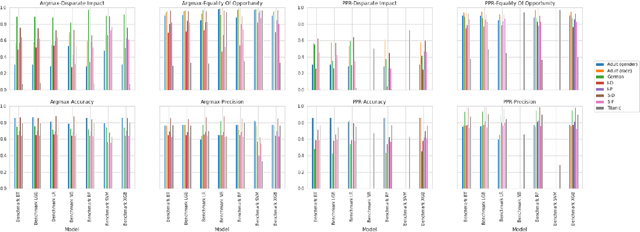
Understanding and removing bias from the decisions made by machine learning models is essential to avoid discrimination against unprivileged groups. Despite recent progress in algorithmic fairness, there is still no clear answer as to which bias-mitigation approaches are most effective. Evaluation strategies are typically use-case specific, rely on data with unclear bias, and employ a fixed policy to convert model outputs to decision outcomes. To address these problems, we performed a systematic comparison of a number of popular fairness algorithms applicable to supervised classification. Our study is the most comprehensive of its kind. It utilizes three real and four synthetic datasets, and two different ways of converting model outputs to decisions. It considers fairness, predictive-performance, calibration quality, and speed of 28 different modelling pipelines, corresponding to both fairness-unaware and fairness-aware algorithms. We found that fairness-unaware algorithms typically fail to produce adequately fair models and that the simplest algorithms are not necessarily the fairest ones. We also found that fairness-aware algorithms can induce fairness without material drops in predictive power. Finally, we found that dataset idiosyncracies (e.g., degree of intrinsic unfairness, nature of correlations) do affect the performance of fairness-aware approaches. Our results allow the practitioner to narrow down the approach(es) they would like to adopt without having to know in advance their fairness requirements.