 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommon Failure Modes of Subcluster-based Sampling in Dirichlet Process Gaussian Mixture Models -- and a Deep-learning Solution
Mar 25, 2022
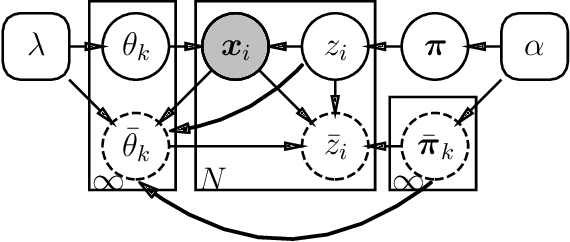
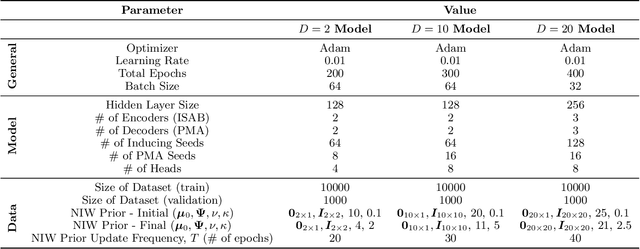
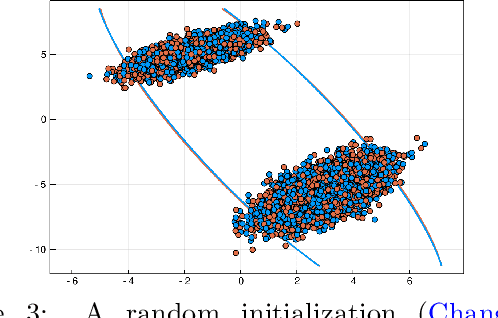
The Dirichlet Process Gaussian Mixture Model (DPGMM) is often used to cluster data when the number of clusters is unknown. One main DPGMM inference paradigm relies on sampling. Here we consider a known state-of-art sampler (proposed by Chang and Fisher III (2013) and improved by Dinari et al. (2019)), analyze its failure modes, and show how to improve it, often drastically. Concretely, in that sampler, whenever a new cluster is formed it is augmented with two subclusters whose labels are initialized at random. Upon their evolution, the subclusters serve to propose a split of the parent cluster. We show that the random initialization is often problematic and hurts the otherwise-effective sampler. Specifically, we demonstrate that this initialization tends to lead to poor split proposals and/or too many iterations before a desired split is accepted. This slows convergence and can damage the clustering. As a remedy, we propose two drop-in-replacement options for the subcluster-initialization subroutine. The first is an intuitive heuristic while the second is based on deep learning. We show that the proposed approach yields better splits, which in turn translate to substantial improvements in performance, results, and stability.